Linuxfr.org
LibreOffice 25.2 : ODF 1.4, interface et traduction
Un petit aperçu de cette nouvelle version de la suite bureautique sortie le 6 février 2025. Cela ne saurait remplacer la lecture des Notes de version dont la lecture est grandement conseillée car elle est exhaustive. On relèvera dans le cadre de cette dépêche principalement ce qui concerne l’interface, les aspects linguistiques, la compatibilité et l’interopérabilité.
La plupart des captures d’écran de cette dépêche ont été faites avec un thème personnel. L’apparence, notamment au niveau des couleurs, de votre LibreOffice sera donc différente. C’est un parti pris assumé.
- lien nᵒ 1 : LibreOffice
- lien nᵒ 2 : Les notes de la version 25.2
- lien nᵒ 3 : LibreOffice 24.8 : fonctions, fonctionnalités, améliorations et nouveautés
- lien nᵒ 4 : Soutenir LibreOffice
- lien nᵒ 5 : Les extensions et modèles
- lien nᵒ 6 : Introduction ODF 1.4, brouillon
- lien nᵒ 7 : Annonce de la sortie de LibreOffice 25.2.1
- lien nᵒ 8 : Annonce de la sortie de la version 25.2
- L’interface
- ODF 1.4, compatibilité et interopérabilité
- Traduction et langues
- Quelques statistiques sur cette version
Pour rappel depuis plusieurs versions, il est possible d’afficher une interface soit « classique » avec des barres d’outils, soit sous la forme d’onglets avec des variantes, par exemple « barre d’outils standard » et « barre d’outils unique » ou encore « onglets » et « onglets compacts ». On peut décider d’appliquer ces changements à toute la suite ou à seulement une application de la suite. Cela se passe dans Affichage > Interface. C’est pris en compte immédiatement.
On pouvait déjà aussi choisir, dans Outils > Options > Affichage un jeu d’icônes et leur taille et, dans Outils Options > Apparence paramétrer quelques couleurs et choisir entre un thème clair et un thème sombre. Avec cette version, on peut tout configurer ou presque en créant un nouveau thème, on peut même en ajouter d’autres. Pour l’instant, le site des extensions et modèles de LibreOffice en propose cinq (il n’y en avait que trois à la sortie de la version). Pour récupérer un thème, cliquer sur le bouton à droite des thèmes (1), il téléchargera et installera le thème de votre choix. On peut préférer de faire le thème soi-même ou d’en modifier un en cliquant sur la flèche à droite des items (2). Les changements se font après un redémarrage.
En théorie, on peut avoir une image en fond de l’application, en pratique, cela doit dépendre des environnements de bureau ou de certains paramètres avancés. Avec ma configuration, Mageia 9 + Xfce cela ne s’affiche pas. Au niveau des changements de couleur : il faut faire attention aux rapports de contraste.
En haut (1) un aperçu du thème « automatique » et en dessous (2) un aperçu du mien. Dans les deux cas, l’interface est en mode barre d’outils unique, mais avec une barre d’outils très très personnalisée. Ça ne se voit pas trop sur la capture.
On peut ainsi également configurer la couleur des caractères non imprimables tels que les marques de paragraphes ¶.
Dans les autres avancées ergonomiques bienvenues : on peut choisir de n’afficher dans le menu Fichier > Derniers documents utilisés que les documents du « module actuel », donc soit uniquement les fichiers de Writer ou de Calc ou d’Impress ou de Draw ou de Base, soit tous les fichiers, les fichiers épinglés restant au-dessus de la liste quels qu’ils soient. Dans Writer : on peut gérer la liste des modifications dans le volet latéral (que vous devriez systématiquement avoir affiché tellement il est utile). Calc a une nouvelle boite de dialogue qui permet de sélectionner ou supprimer les doublons : Données > Duplicates et l’assistant Fonction a été amélioré pour permettre de les trouver plus facilement.
La boite de dialogue de recherche des doublons
LibreOffice 25.02 est compatible avec la version 1.4 du format Open Document (ODF) qui, semble-t-il n’a pas encore fait l’objet d’une sortie officielle. En tout cas, ça n’est pas signalé sur la page consacrée aux annonces (en) concernant ce format. A priori, la version 14.4 n’est donc pas encore officiellement un standard OASIS (en) tout en étant semble-t-il prêt pour l’être si on croit cette discussion (en).
Par défaut les fichiers sont au format ODF 1.4.Extended. Ce qui peut se modifier au niveau du menu Outils > Options Chargement/enregistrement.
On notera que, plus les versions ODF évoluent, moins les suites bureautiques qui n’ont pas fait évoluer le support des formats et les vieilles versions de LibreOffice pourront ouvrir et travailler correctement les nouveaux fichiers s’ils sont complexes.
Indépendamment de la prise en compte du format ODF 1.4, le développement de LibreOffice a continué à travailler sur d’autres points. Ainsi on a notamment :
- une meilleure récupération des polices lors de l’import d’un fichier .DOCX, l’incorporation des polices au fichier ne suffisant pas toujours pour un bon affichage, notamment en cas de fontes qui doivent être ignorées (en),
- toujours pour Writer, une meilleure interaction avec LOK, (LibreOffice Kit) une bibliothèque de LibreOffice (en),
- dans Calc, le support de l’export et de l’import de connections.xml au format OOXML, qui permet un meilleur import des fichiers au format XLSX et évite des pertes de données, rapport de bug 158857 (en),
- le support de macOS Quick Look, une application de Mac OS qui permet de visualiser tous les fichiers sans avoir à les ouvrir, dans LibreOffice 25.02, elle prend en charge les formats de fichiers les plus courants de la suite (en),
- et une mise à jour en version 0.1.8 de libvisio, une bibliothèque de LibreOffice (en) qui sert pour la gestion des fichiers au format Microsoft Visio, le logiciel de création d’organigrammes et de diagrammes de Microsoft.
Cette version, comme on peut le voir sur les captures d’écrans précédentes, n’est pas intégralement traduite. La traduction de l’interface était assurée par Jean-Baptiste Faure qui passe la main. LibreOffice a donc besoin de volontaires pour assurer la localisation de l’application en français. Si cela vous intéresse, envoyez un courriel à la liste de discussion francophone discuss@fr.libreoffice.org. La liste est modérée, même si vous n’y êtes pas abonné·e, la modération l’enverra sur la liste. Un très très grand merci à Jean-Baptiste pour toutes ces années.
Ceci est indépendant du fait que le français de la République de Guinée (fr-GN) existe maintenant comme langue par défaut des fichiers et pour le formatage spécifique à la région.
Les dictionnaires orthographiques pour l’anglais (GB et ZA), le danois, le mongol, le thaï, le coréen, l’ukrainien et le slovaque ont été mis à jour. Le support pour le thésaurus et l’AutoCorrection thaï a été ajouté tandis que le thésaurus slovène a été mis à jour. Ces dictionnaires peuvent être ajoutés à LibreOffice sous la forme d’extensions (en) ainsi que les correcteurs orthographiques.
Si cela vous intéresse, il existe même une extension (en) développée par les Ministères économiques et financiers français, TerMef qui « est le gestionnaire des référentiels terminologiques des Ministères économiques et financiers (Mef) au format de l’internet sémantique. » Elle vous donne les définitions officielles des termes, pas uniquement en informatique, susceptibles d’être utiles dans les rapports avec l’administration française, on aura donc une définition de « format » et une définition de « formation professionnelle ».
Cette extension, qui s’affiche dans le volet latéral. On entre le terme recherché avec les options voulues et on appuie sur le premier bouton à gauche (1)1. L’extension vous sort une série de définition, en cliquant sur celle qui nous intéresse (2), ici « Formater », elle affiche la notice du terme. L’extension est sous licence MPL (en).
Au 13 février, selon le blog de la suite (en), donc après une semaine, LibreOffice 25.2 aura été téléchargée directement 647 961 fois. Son annonce sur les différents réseaux sociaux, dont Mastodon a été vue, partagée, aimée et commentée 11 313 fois.
À noter : la première mise à jour mineure, 25.2.1 vient de sortir, le 27 février (au moment où je termine enfin la rédaction de cette dépêche).
Un très grand merci à celles et ceux qui font de LibreOffice une superbe suite bureautique.
-
J’imagine que les boutons ont des icônes spécifiques, mais elles ne s’affichent pas ici. ↩
Commentaires : voir le flux Atom ouvrir dans le navigateur
Revue de presse de l’April pour la semaine 9 de l’année 2025
Cette revue de presse sur Internet fait partie du travail de veille mené par l’April dans le cadre de son action de défense et de promotion du logiciel libre. Les positions exposées dans les articles sont celles de leurs auteurs et ne rejoignent pas forcément celles de l’April.
- [ZDNET] Décès de Jean-Pierre Archambault, pionnier du logiciel libre dans les écoles
- [La Tribune] Open source (d'inspiration)
- [Le Monde.fr] Revente de jeux vidéo dématérialisés: UFC-Que choisir saisit la Commission européenne
- [L'OBS] “Quand on rejoint Wikipédia, c'est pour rendre le monde meilleur, pas pour brimer ou détruire”
- [ZDNET] Après son départ de X, les conseillers parisiens proposent que Paris crée un serveur mastodon
- lien nᵒ 1 : April
- lien nᵒ 2 : Revue de presse de l'April
- lien nᵒ 3 : Revue de presse de la semaine précédente
- lien nᵒ 4 :
Agenda du Libre pour la semaine 10 de l’année 2025
Calendrier Web, regroupant des événements liés au Libre (logiciel, salon, atelier, install party, conférence), annoncés par leurs organisateurs. Voici un récapitulatif de la semaine à venir. Le détail de chacun de ces 51 événements (France : 47, internet : 3, Belgique : 1, Québec : 1) est en seconde partie de dépêche.
- lien nᵒ 1 : April
- lien nᵒ 2 : Agenda du Libre
- lien nᵒ 3 : Carte des événements
- lien nᵒ 4 : Proposer un événement
- lien nᵒ 5 : Annuaire des organisations
- lien nᵒ 6 : Agenda de la semaine précédente
- lien nᵒ 7 : Agenda du Libre Québec
-
- [FR Montpellier] Émission | Radio FM-Plus | Temps Libre | Diffusion - Le lundi 3 mars 2025 de 09h00 à 10h00.
- [CA-QC Montréal] Rencontres-Linux Québec - Le mardi 4 mars 2025 de 17h30 à 21h30.
- [FR Paris] Protéger ses pratiques numériques - Du lundi 3 mars 2025 à 09h30 au mardi 4 mars 2025 à 18h00.
- [FR Nantes] 23 bonnes raisons pour adopter l’éducation ouverte - Du lundi 3 mars 2025 à 10h00 au vendredi 28 mars 2025 à 11h00.
- [FR Martigues] Culture WEB - Le lundi 3 mars 2025 de 17h00 à 19h00.
- [FR Saint-Nazaire-en-Royans] Permanence Rézine Cambuse - Le lundi 3 mars 2025 de 17h30 à 19h30.
- [FR Bègles] Soirée découverte de Linux spécial grands débutants - Le lundi 3 mars 2025 de 18h30 à 20h30.
- [FR Limoges] ExpoLibre - Du mardi 4 mars 2025 à 10h00 au samedi 29 mars 2025 à 18h00.
- [internet] Émission «Libre à vous!» - Le mardi 4 mars 2025 de 15h30 à 17h00.
- [FR Montpellier] Atel'libre | Modélisez et animez vos images 3D avec Blender - Le mardi 4 mars 2025 de 17h00 à 19h00.
- [FR Grenoble] Permanence Rézine - Le mardi 4 mars 2025 de 19h00 à 20h00.
- [FR Croix] Atelier Local-Low-Tech - Le mardi 4 mars 2025 de 19h00 à 22h00.
- [internet] Permanence numérique (visio) - Le mardi 4 mars 2025 de 20h00 à 21h30.
- [FR Dijon] Editathon Wikipédia - femmes dijonnaises - Le mercredi 5 mars 2025 de 09h00 à 12h00.
- [FR Le Mans] Permanence du mercredi - Le mercredi 5 mars 2025 de 12h30 à 17h00.
- [FR Le Blanc] Ateliers “Libres” - Le mercredi 5 mars 2025 de 14h00 à 17h00.
- [FR Le Blanc] Ateliers “Libres” - Le mercredi 5 mars 2025 de 14h00 à 14h00.
- [FR Pessac] Cours gratuit d’Espéranto, langue Libre - Le mercredi 5 mars 2025 de 17h30 à 19h00.
- [FR Beauvais] Sensibilisation et partage autour du Libre - Le mercredi 5 mars 2025 de 18h00 à 20h00.
- [FR Orchies] Mercredis Linux - Le mercredi 5 mars 2025 de 19h30 à 23h30.
- [FR Montpellier] ROBOTOP’IA (Robotique et IA, futur d’une rencontre) - Le jeudi 6 mars 2025 de 09h15 à 17h30.
- [FR Martigues] Premiers pas avec Linux - Le jeudi 6 mars 2025 de 10h00 à 12h00.
- [FR Joué-lès-Tours] Atelier du Libre - Le jeudi 6 mars 2025 de 13h30 à 16h00.
- [FR Montpellier] Atel'libre | PAO : Gimp, Inkscape, Scribus, Krita - Le jeudi 6 mars 2025 de 17h00 à 19h00.
- [FR Chambéry] Repair du libre - Le jeudi 6 mars 2025 de 18h00 à 20h00.
- [FR Angers] Rencontre mensuelle OpenStreetMap - Le jeudi 6 mars 2025 de 18h15 à 19h15.
- [FR Béziers] Permanence | GNU/Linux et Logiciels Libres - Le jeudi 6 mars 2025 de 18h30 à 21h00.
- [FR Montrouge] Rencontre contributeurs OpenStreetMap Sud de Paris - Le jeudi 6 mars 2025 de 19h00 à 22h00.
- [FR via Internet] Permanence numérique en visio - Le jeudi 6 mars 2025 de 20h00 à 21h30.
- [internet via Internet] Permanence numérique en visio - Le jeudi 6 mars 2025 de 20h00 à 21h30.
- [FR Chambery] Forum Alpinux - Le jeudi 6 mars 2025 de 20h00 à 22h00.
- [FR Nantes] Bureautique accessible - Le vendredi 7 mars 2025 de 09h00 à 17h00.
- [FR Quimperlé] Point info GNU/Linux - Le vendredi 7 mars 2025 de 13h30 à 17h30.
- [FR Figeac] Café bidouille, réparation informatique - Le vendredi 7 mars 2025 de 14h00 à 17h00.
- [FR Anglet] Rencontre Mapadour (groupe local OSM) - Le vendredi 7 mars 2025 de 16h00 à 19h00.
- [FR Milly-sur-Thérain] Sensibilisation et partage autour du Libre - Le vendredi 7 mars 2025 de 17h00 à 19h00.
- [BE Antoing] Atelier Linux - Le vendredi 7 mars 2025 de 18h00 à 20h00.
- [FR Paris] Soirée « radio ouverte » au studio de Cause Commune - Le vendredi 7 mars 2025 de 19h30 à 22h00.
- [FR Annecy] Réunion hebdomadaire AGU3L Logiciels Libres - Le vendredi 7 mars 2025 de 20h00 à 23h59.
- [FR Marignier] Utilisation d’internet - Le samedi 8 mars 2025 de 09h00 à 12h00.
- [FR Villeneuve d’Ascq] Ateliers « Libre à vous » - Le samedi 8 mars 2025 de 09h00 à 12h00.
- [FR Lézignan-Corbières] Atelier au fablab de Lézignan-Corbières - Le samedi 8 mars 2025 de 10h00 à 12h00.
- [FR Bégard] Permanence infothema à Bégard (Groupe 1) - Le samedi 8 mars 2025 de 10h00 à 12h00.
- [FR Lézignan-Corbières] Initiation à un logiciel libre de dessin vectoriel - Le samedi 8 mars 2025 de 10h00 à 12h00.
- [FR Ivry sur Seine] Cours de l’École du Logiciel Libre - Le samedi 8 mars 2025 de 10h30 à 18h30.
- [FR Quimperlé] Install Party GNU/Linux - Le samedi 8 mars 2025 de 14h00 à 17h30.
- [FR Fontenay-le-Fleury] Conférence : Droit & Image – Ce que vous pouvez (ou pas) faire avec vos photos ! - Le samedi 8 mars 2025 de 14h00 à 17h00.
- [FR Le Havre] Install partie - Le samedi 8 mars 2025 de 14h00 à 17h00.
- [FR Nantes] Permanence Linux-Nantes - Le samedi 8 mars 2025 de 15h00 à 18h00.
- [FR Quimper] Permanence Linux Quimper - Le samedi 8 mars 2025 de 16h00 à 18h00.
- [FR Vandœuvre-lès-Nancy] Atelier modélisation boitier d’un capteur de distance - Le dimanche 9 mars 2025 de 10h00 à 13h00.
- [FR St Caprais de bordeaux] Ğmarché - Le dimanche 9 mars 2025 de 10h00 à 15h00.
Montpel'libre réalise une série d’émissions régulières à la Radio FM-Plus intitulées « Temps Libre ». Ces émissions sont la présentation hebdomadaire des activités de Montpel’libre.
Après le jingle où l’on présente brièvement Montpel'libre, nous donnerons un coup de projecteur sur les activités qui seront proposées prochainement.
Ces émissions seront l’occasion pour les auditeurs de découvrir plus en détails les logiciels libres et de se tenir informés des dernières actualités sur le sujet.
Alors, que vous soyez débutant ou expert en informatique, que vous ayez des connaissances avancées du logiciel libre ou que vous souhaitiez simplement en savoir plus, Montpel'libre, au travers de cette émission, se fera un plaisir pour répondre à vos attentes et vous accompagner dans votre découverte des logiciels libres, de la culture libre et des communs numériques.
Vous vous demandez peut-être ce qu’est un logiciel libre. Il s’agit simplement d’un logiciel dont l’utilisation, la modification et la diffusion sont autorisées par une licence qui garantit les libertés fondamentales des utilisateurs. Ces libertés incluent la possibilité d’exécuter, d’étudier, de copier, d’améliorer et de redistribuer le logiciel selon vos besoins.
Inscription | GPS 43.60524/3.87336
Fiche activité:
https://montpellibre.fr/fiches_activites/Fiche_A5_017_Emission_Radio_Montpellibre_2024.pdf
- Radio FM-Plus, 4 rue Saint Barthelemy, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, radio, fm-plus, temps-libre, diffusion
Local de la rencontre: École de Technologie Supérieure A-13??
Rencontre virtuelle: https://bbb3.services-conseils-linux.org/Linux-Meetup
17:30 à 19:00 - 5 à 7 virtuel et en présentiel
Rejoignez-nous pour un moment de détente et de convivialité lors de notre 5 à 7. Que vous préfériez nous retrouver au Resto-Pub 100 Génies de l’ÉTS ou en ligne sur BigBlueButton (BBB), l’essentiel est de partager un moment agréable. Si vous avez l’intention de venir en personne, veuillez nous en informer afin de pouvoir réserver suffisamment de place pour vous.
18:30 à 19:00 - Installation et tests de l’environnement hybride (tests de son et vidéo)
19:00 à 21:30 - Programmation de la rencontre
- Accueil et mot de bienvenue
- Capsule éducative [? ?]
- Présentation [? ?]
- Une période d’échange de trucs et astuces sous Linux, où chacun est encouragé à partager ses connaissances.
Extras
Que vous soyez débutant ou expert, étudiant ou professionnel, cette réunion est ouverte à tous. Elle réunit une diversité de personnes, allant des gestionnaires aux programmeurs, des professeurs aux retraités, unissant ainsi des esprits passionnés par les logiciels libres, quel que soit votre domaine d’expertise.
Rejoignez-nous pour cette opportunité exceptionnelle de socialiser, d’apprendre, et de tisser des liens avec d’autres passionnés. Ensemble, nous pouvons approfondir notre compréhension des logiciels libres et contribuer à une communauté dynamique.
La participation est gratuite, et nous avons hâte de vous rencontrer, que ce soit en personne ou en ligne. Inscrivez-vous dès maintenant pour recevoir le lien de la réunion virtuelle, et pensez à nous informer si vous prévoyez de vous joindre à nous au Resto-Pub 100 Génies de l’ÉTS.
Au plaisir de partager cette soirée exceptionnelle avec vous!
Cordialement,
Martial
P.S.: Pour le transport en commun : Station de métro Bonaventure
- École de Technologie Supérieure et virtuel, ÉTS - Pavillon A, 1100, rue Notre-Dame Ouest, Montréal, Montréal, Québec
- https://www.rencontres-linux.quebec/
- linux-meetup-montréal, rencontres-linux-québec
Cette formation présente une démarche d’analyse des menaces dans les activités associatives, militantes ou personnelles, dans des contextes d’utilisation d’outils numériques. Elle propose également des logiques de sécurisation des pratiques.
Sauf à ne rien faire, il n’existe pas de situation ou de solution « parfaitement sécurisée ». Il est néanmoins pertinent de réfléchir aux intérêts de protéger ses pratiques numériques. Dans de nombreuses situations cela est plus que nécessaire : pour prendre soin de soi ou des personnes avec qui l’on s’organise ou que l’on aide et/ou pour être plus efficace dans la poursuite de nos objectifs politiques et sociaux.
Cette formation propose des méthodes et outils pour penser la sécurisation de ses pratiques, notamment informatiques, comme un processus. Elle permet d’évaluer les outils numériques utilisés ou envisagés au regard de la nature des activités, des menaces existantes, des informations et des correspondant·es que vous cherchez à protéger. Sans offrir de solution « clé en main », elle propose un cadre pour commencer à améliorer la sécurisation de ses activités en accord avec ses objectifs et les contraintes existantes.
Lors de la dernière session de formation, en mars 2024, le taux de satisfaction des stagiaires était de 4,9/5. Iels ont particulièrement apprécié « le partage des expériences avec les autres participant⋅es » et « le cadre posé sans jugement de valeurs ou des pratiques. ». Parmi les expressions employées par les participant·es pour décrire la formation, citons: « Sécuriser c’est un processus de soin » et « La sécurisation des pratiques est une affaire collective ».
À qui s’adresse cette formation?
La formation est ouverte à toute personne soucieuse d’améliorer la protection de ses pratiques numérique. Elle s’adresse en particulier aux acteur·ices du milieu associatif souhaitant adopter de bonnes pratiques en matière d’autodéfense numérique et accompagner ces évolutions dans leurs organisations.
Objectifs pédagogiques
- Savoir mettre en place un modèle des risques et des menaces liées à nos pratiques informationnelles – principalement numériques - au sein de nos structures.
- Mieux comprendre les menaces de surveillance pesant sur les échanges numériques.
- Découvrir ou mieux comprendre des bonnes pratiques permettant d’améliorer la sécurité de nos activités informatiques.
- Améliorer ses capacités à diffuser et faciliter l’adoption d’une évolution des pratiques de sécurisation dans ses organisations.
Déroulé
- Enjeux de la surveillance, individuellement et collectivement: éléments de compréhension politiques, juridiques et techniques.
- Sécurisation des pratiques, réduction des risques: une approche collective et de soin.
- Modélisation de la menace et processus de planification de sécurité opérationnelle.
- Logiques de sécurisation des pratiques et de mise en place d’outils face aux contraintes.
- Présentation et analyse d’outils numériques de protection et possible prise en main.
- Enjeux juridiques sur la protection des données.
- Échanges et accompagnement éventuel sur des enjeux concrets liés aux problématiques des participant·es (outils, enjeux juridiques, diffusion au sein d’une organisation…).
Méthode mobilisée et évaluations
La formation est animée de façon à permettre à chacun·e·de partir de ses besoins en les partageant avec les autres participant‧e‧s afin de construire une analyse commune. Un éclairage méthodologique et technique adapté au niveau des participant⋅es est assuré par les formateur⋅ices.
Chaque temps est rythmé par des apports théoriques, de l’expérimentation collective et des travaux en petits ou grand groupe. Tous ces temps se déroulent de façon participative, de manière à s’appuyer sur l’expérience et les savoirs des participant·es et d’être en mesure de répondre à leurs attentes, besoins et interrogations. Une évaluation des connaissances est réalisée en amont, puis à mi-parcours et à la clôture de l’action de formation.
Pré-requis
Participer à la formation en tant que membre d’un collectif.
Cette formation est dispensée en langue française.
Matériel requis
Idéalement, mais non obligatoire, amener un ordinateur portable et/ou un smartphone équipé d’un système d’exploitation à jour et en avoir un usage courant pour pouvoir réaliser certaines des expérimentations et découvertes d’outils proposées.
La fiche « FormationsNumérique_ MatérielNécessaire_ritimo_25.pdf », détaille les équipements matériels et logiciels nécessaires pour suivre cette formation, et précise les points d’attention y afférents.
Formatrice et intervenant
Mélissa Richard, chargée d’animation numérique pour le réseau ritimo et
Sx, militant engagé dans la défense des libertés en ligne et hors ligne, juriste bidouilleur, auteur du « Guide de Survie des Aventuriers du Net » (édité par l’association CECIL).
Informations pratiques
- Dates: lundi 3 et mardi 4 mars 2025
- Durée: 2 jours, soit 14 heures de formation
- Modalité de formation: en présentiel
- Lieu: au CICP, 21ter rue Voltaire, 75011 PARIS
- Horaires: de 9h30 à 18h
- Nombre de participant·es minimum: 6 personnes
- Nombre de participant·es maximum: 15 personnes
- Date limite d’inscription: 18 février 2025
- Note pour les personnes bénéficiaires de la formation professionnelle: il est fortement recommandé de s’inscrire au plus tard un mois avant la formation pour que nous puissions vous faire parvenir devis et convention.
Précautions sanitaires
Nos formations en présentiel se déroulent dans le respect des gestes barrières et d’un protocole sanitaire mis en place pour la protection de tou·tes (mis à jour en fonction de l’évolution de la situation).
Accessibilité
Toutes les salles accueillant nos formations sont accessibles aux personnes à mobilité réduite. Si vous avez d’autres besoins nécessitant que nous adaptions nos modalités pédagogiques, contactez-nous soit à l’adresse mail mentionnée ci-dessous, soit par téléphone, ou précisez-le dans le formulaire de demande d’inscription.
Frais pédagogiques de formation
- 30 euros – étudiant·es et chômeur·ses (sur justificatif)
- 60 euros - bénévoles, volontaires des membres et relais ritimo et Coredem
- 80 euros - bénévoles, volontaires d’autres associations
- 600 euros - salarié·es bénéficiaires de la formation professionnelle
Inscription
Pour faire une demande d’inscription, merci de compléter le formulaire de demande d’inscription.
Une fois votre demande d’inscription validée, nous vous demanderons de nous faire parvenir un acompte de 15 euros à l’ordre de ritimo (21 ter rue Voltaire 75011 Paris) pour confirmer votre inscription. Celui-ci sera encaissé si vous annulez votre participation moins de deux semaines avant la formation.
- CICP, 21 ter, rue Voltaire, Paris, Île-de-France, France
- https://www.ritimo.org/Proteger-ses-pratiques-numeriques-mars-10692?id_evenement=2849
- ritimo, logiciel-libre, formation, sécurité, atelier
23 bonnes raisons pour adopter l’éducation ouverte
La chaire UNESCO RELIA avec l’aide du réseau UNOE et de l’Université européenne du bien-être EUniWell propose une initiative inédite pour participer à la semaine internationale de l’éducation ouverte OEWeek, promue par Open Éducation Global: 23 bonnes raisons pour adopter l’éducation ouverte
Le projet est simple:
- Une publication d’un article par jour durant tout le mois de mars sur 3 blogs.
- Chaque article promeut un argument pour convaincre d’opter pour l’éducation ouverte
- Des contributions du monde entier: 23 contributeurs dont 3 de Nantes Université, 13 pays représentés, dans 8 langues.
- Toutes les contributions seront sous Licence Créative Commons BY, pour en faciliter les diffusions et réutilisations.
Rendez-vous sur le blog de la Chaire Relia pour vous laisser convaincre chaque jour un peu plus qu’il faut adopter l’éducation ouverte !
- Nantes, Pays de la Loire, France
- https://chaireunescorelia.univ-nantes.fr/2025/03/03/pour-decouvrir-23-raisons-en-faveur-de-leducation-ouverte-cest-par-ici/
- éducation-ouverte, éducation, multilinguisme, chaire-unesco-relia
Les Espaces publics numériques (EPN) vous proposent une séance pour découvrir l’actualité du net, mais également bien d’autres sujets !
Présentation
« Fake news », actualités, culture geek, réseaux sociaux, darknet, cryptomonnaie, l’univers du « libre », l’écologie numérique, l’impact du digital sur l’environnement, les réflexes à adopter… Une séance pour décrypter toute l’actualité du numérique en compagnie des médiateurs numériques.
En savoir plus
Cette activité fait partie de l’ensemble des ateliers collectifs proposés par les Espaces Publics Numériques (EPN) de la ville de Martigues.
Ces ateliers vont vous permettre de découvrir dans la convivialité des outils et des usages numériques utiles en fonction de votre niveau.
Il s’agit d’ateliers collectifs encadrés par des médiateurs numériques.
- Nos espaces sont labellisés SUD LABS par la Région Sud Provence-Alpes-Côte-d’Azur.
- inscription possible sur https://logen.ville-martigues.fr
Retrouvez-nous sur Facebook
EPN Maison de la Formation et Jeunesse, quai Lucien Toulmond, Martigues, Provence-Alpes-Côte d’Azur, France
https://www.ville-martigues.fr/services-en-ligne/martigues-numerique/espaces-publics-numeriques
Rézine est un fournisseur d’accès à Internet qui défend une vision politique des technologies et des réseaux. Pour cela, Rézine met notamment en œuvre un accès Internet local, à prix juste, respectant la neutralité du Net, piloté par ses usagères et usagers, dans une démarche émancipatrice.
Nous fournissons Internet via la fibre, via wifi (radio) et proposons également des VPN.
Par ailleurs fournir une critique du numérique, et en particulier des réseaux, est une activité inhérente à notre activité de fournisseur d’accès à Internet, que nous avons affirmée dans l’objet de la structure. Nous inscrivons notre démarche dans une tradition d’éducation populaire, qui vise à contribuer à l’émancipation des personnes, dans leur rapport aux technologies et aux réseaux, quel que soit leur niveau de connaissance.
Venez nous rencontrer pour discuter, devenir membre, poser vos questions sur la fibre, sur Internet, ou juste par curiosité!
- Les BonBONs du Vercors, 1 rue des Mariniers, Saint-Nazaire-en-Royans, Auvergne-Rhône-Alpes, France
- https://www.rezine.org
- fai, connectivité, fibre, ftth, radio, rézine, éducation-populaire, permanence
Lundi 3 mars 2025 à 18h30 à la ZAP
« Peut-on éviter d’acheter un nouvel ordinateur en installant Linux sur son vieux matos ? Le logiciel libre, c’est anticapitaliste ? Ma vie privée est-elle mieux protégée avec l’informatique libre ? »
Avec humour et esprit de synthèse, Antony, ancien journaliste, désormais webmaster épris de numérique responsable, vous emmène dans une ballade déconcertante et instructive dans un monde de gnous et de manchots pour répondre à ces questions et toutes celles qu’on peut se poser quand on est novice en la matière.
Cette présentation sera suivie d’une session (libre, forcément !) d’expérimentation ludique de différents systèmes d’exploitation libres à explorer soi-même, avec deux utilisateurs confirmés à vos côtés. À recommander à tous, curieux, déjà convaincus et sceptiques…
Également aux parents qui souhaitent éveiller leurs enfants avec un système adapté à leurs besoins, aux membres d’associations avec un parc d’ordinateurs plus ou moins vieillissant… et tout particulièrement à ceux qui cherchent à sauver leur ordinosaure et/ou à aligner leurs valeurs idéalistes avec la réalité de leur quotidien informatique.
Repas en auberge espagnole : apportez de quoi grignoter ! Boissons en vente sur place.
Merci de vous inscrire pour aider les organisateurs à prévoir la logistique (adresse de courriel requise pour l’inscription, vous recevrez simplement un rappel le week-end précédent l’événement).
PS: je ne suis pas l’organisateur, je publie juste cette information qui mérite d’être partagée.
- ZAP : Zone À Partager, 1 place du 14 Juillet, Bègles, Nouvelle-Aquitaine, France
- https://zoneapartager.org
- linux, vie_privée, gnu-linux, logiciels-libres, découverte
_________________________________________________________
ExpoLibre (une expo sur le logiciel libre:D)
Expolibre est un ensemble de panneaux destinés au grand public qui présentent la philosophie du logiciel libre, mouvement qui se développe depuis le début des années 80, et expliquent ce que sont les logiciels libres. L’objectif est de sensibiliser aux enjeux de société liés à cette révolution informatique.
Dans l’esprit du logiciel libre, cette exposition est « libre » et nous vous invitons à la télécharger pour la diffuser, la copier, l’exposer ou l’adapter.
L’Expolibre a été réalisée par le groupe sensibilisation de l’April, dont l’objectif est la production, l’inventaire et l’amélioration des ressources de communication autour du logiciel libre, à des fins de promotion et de sensibilisation du public à ces enjeux.
Pour en savoir plus sur l’Expolibre : www.expolibre.org.
(plus d’informations auprès de la Bfm centre-ville: 05 55 45 96 53)
Exposition proposée par le réseau des Bfm de Limoges
dans le cadre du Mois Du Logiciel Libre.
- Bfm Limoges, 2 place Aimé Césaire, Limoges, Nouvelle-Aquitaine, France
- libre-en-fete-2025, bfm, bfm_limoges, bibliothèque-francophone-multimédia, mdll, logiciels-libres, exposition, expolibre
L’émission Libre à vous! de l’April est diffusée chaque mardi de 15 h 30 à 17 h sur radio Cause Commune sur la bande FM en région parisienne (93.1) et sur le site web de la radio.
Le podcast de l’émission, les podcasts par sujets traités et les références citées sont disponibles dès que possible sur le site consacré à l’émission, quelques jours après l’émission en général.
Les ambitions de l’émission *Libre à vous!*
Découvrez les enjeux et l’actualité du logiciel libre, des musiques sous licences libres, et prenez le contrôle de vos libertés informatiques.
Donner à chacun et chacune, de manière simple et accessible, les clefs pour comprendre les enjeux mais aussi proposer des moyens d’action, tels sont les objectifs de cette émission hebdomadaire.
L’émission dispose:
- d’un flux RSS compatible avec la baladodiffusion
- d’une lettre d’information à laquelle vous pouvez vous inscrire (pour recevoir les annonces des podcasts, des émissions à venir et toute autre actualité en lien avec l’émission)
Radio Cause Commune,
C’est avec un grand plaisir que nous vous annonçons cette réunion du groupe Blender à Montpellier. (Le premier mardi de chaque mois).
Rencontrer le groupe local d’utilisateurs du logiciel de modélisation 3D Blender pour échanger et actualiser ses connaissances sur ce logiciel à la fois très puissant et riche en potentialités. Attention, il ne s’agit pas d’ateliers d’initiation à Blender.
Les thèmes que nous vous proposons d’aborder :
Le programme :
- Initiation à Blender
- les activités du Groupe Blender
- premiers pas dans l’univers 3d
- prise en main des outils de base
- inscriptions aux formations Blender
Blender est un logiciel libre de modélisation, d’animation et de rendu en 3D. Cette réunion se veut pour partager du temps autour du projet, s’entre-aider, s’émuler, s’amuser, produire, ou tout simplement discuter. Cette réunion s’adresse à toutes les personnes débutantes, confirmées et même curieuses de l’image en 3D.
Ces rencontres du groupe Blender ont lieu le premier mardi de chaque mois de 17h00 à 19h00.
Sur inscription | GPS 43.60859/3.89329
- La Fabrique, médiathèque Émile Zola, 218 boulevard de l’Aéroport international, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, logiciels-libres, blender, 3d, image, atelier-libre
Rézine est un fournisseur d’accès à Internet qui défend une vision politique des technologies et des réseaux. Pour cela, Rézine met notamment en œuvre un accès Internet local, à prix juste, respectant la neutralité du Net, piloté par ses usagères et usagers, dans une démarche émancipatrice.
Nous fournissons Internet via la fibre, via wifi (radio) et proposons également des VPN.
Par ailleurs fournir une critique du numérique, et en particulier des réseaux, est une activité inhérente à notre activité de fournisseur d’accès à Internet, que nous avons affirmée dans l’objet de la structure. Nous inscrivons notre démarche dans une tradition d’éducation populaire, qui vise à contribuer à l’émancipation des personnes, dans leur rapport aux technologies et aux réseaux, quel que soit leur niveau de connaissance.
Venez nous rencontrer pour discuter, devenir membre, poser vos questions sur la fibre, sur Internet, ou juste par curiosité!
- Collectif Voisin, place André Charpin, Grenoble, Auvergne-Rhône-Alpes, France
- https://www.rezine.org
- fai, connectivité, fibre, ftth, radio, rézine, éducation-populaire, permanence
L’Association Club Linux Nord Pas-de-Calais est présent tous les premiers mardis du mois aux Petites Cantines, à Croix.
Au cours de ces séances, nous vous proposons d’installer le système d’exploitation libre Linux et/ou les logiciels libres que vous utilisez sur votre ordinateur.
Si votre ordinateur est récent et que vous vous voulez vous donner les moyens de maîtriser les informations qui y entrent et en sortent, ou si votre ordinateur devient poussif…
Pensez à nous rendre visite, c’est gratuit et on vous donnera toutes les clés pour que vous puissiez faire le choix qui vous convient
Unvanquished 0.55, enfin là !
Après une longue attente la version 0.55 du jeu Unvanquished a été publiée le 20 octobre 2024. Deux mises à jour mineures se sont succédées le 3 novembre et le 15 décembre pour peaufiner cette version, juste à temps pour être déposée sous le sapin de Noël !
Unvanquished est un jeu vidéo libre et gratuit mêlant stratégie en temps réel et actions à la première personne dans un univers futuristique où deux factions (humains, aliens) combattent pour leur survie.
S’inscrivant dans la continuité de Tremulous (révélé en 2006) et basé sur ce dernier, Unvanquished développe cette expérience de jeu nerveuse et exigeante depuis 2013, en améliorant continuellement le moteur et explorant des variantes et ajustements de jouabilité.
Laisse-moi goûter à cette version !
- lien nᵒ 1 : Unvanquished 0.55: Awesomeness has arrived
- lien nᵒ 2 : Unvanquished 0.55.1, let’s polish it!
- lien nᵒ 3 : Unvanquished 0.55.2: bots in the sky
- lien nᵒ 4 : Des nouvelles de Unvanquished
- lien nᵒ 5 : Unvanquished, 10 ans et Invaincu
- Gameplay
- Bots
- Interface utilisateur
- Traductions
- Nouveaux visuels
- Fichier d’entité
- Le futur est lumineux
- Corrections du moteur de rendu
- Performance améliorées
- Bien entendu que ça fait tourner Unvanquished !
- Nouveaux joujoux
- À venir
- Il est temps de jouer !
Cette version avait été promise dans le dernier article Des nouvelles de Unvanquished, et 10 mois après la version 0.54, voici la version 0.55.
Pendant cette année 2024, le jeu a fait l’objet d’un développement soutenu et vu l’arrivée de nouveaux contributeurs.
Gameplay- La portée du « rocket pod » a été réduite: 2000qu → 1300qu (62m → 40m).
- Il n’est plus possible de désévoluer vers la même classe, ce qui permettait de recharger ses projectiles sans attendre.
- Les bots aliens savent désormais éteindre les bases en feu.
- Ils peuvent aussi utiliser le granger avancé pour atteindre des plate-formes élevées et y construire.
- Les classes sachant marcher sur les murs le font de manière plus fiable, et le saut de mur du maraudeur est plus précis lorsqu’il escalade des murs.
D’autres améliorations sont plus subtiles, les bots peuvent naviguer dans les cartes de façon plus efficace depuis que la taille des tuiles du maillage de navigation est configurable. Les mappers (ceux qui créent ou modifient des cartes) peuvent aussi configurer d’autres aspects de la navigation.
Un déséquilibre qui rendait les bots aliens moins bons que les bots humains a été retravaillé.
La navigation dans la carte perseus a été améliorée. C’est un des patchs de la mise à jour mineure 0.55.1, c’était déjà prêt pour la 0.55 mais avait été oublié (oups !).
La 0.55.2 a donné aux bots la capacité de voler et la capacité de danser autour des ravins sans tomber.
Interface utilisateurIl est désormais possible de se déplacer et d’utiliser certaines touches d’action alors que certains menus circulaires sont ouverts : évolution, construction, balises (beacons). Cela permet d’ouvrir le menu de construction en tant que granger avancé sans tomber. On peut aussi évoluer tout en courant ou en sautant, etc.
Les nouveaux menus avec les options de réticules.
TraductionsLa version 0.55 est la première version majeure d’Unvanquished à distribuer de nouveau des traductions ! Nous avions déjà distribué quelques traductions avec la version de correction 0.54.1, elles étaient en quelques sorte en prévisualisation. Cette version apporte les traductions pour le Français, l’Allemand, l’Italien, l’Espagnol, le Finlandais, deux variantes de Portugais, et trois variantes de Chinois.
Dans les premiers jours d’Unvanquished nous avions des traductions, mais il y a longtemps nous avons changé la technologie utilisée pour implémenter l’interface utilisateur et la prise en charge des traductions a dû être réimplémentée. Les voici de retour et nous sommes heureux de vous les distribuer de nouveau. Pour contribuer plus de traductions et les affiner, le mieux est de le faire sur Weblate.
Nouveaux visuelsDe nouveaux modèles sont là : la « painsaw » d’Alex Tikkoiev et le Chaingun d’extreazz. Ils ont été intégrés au jeu par Ishq. Cela semble simple à faire mais nous n’avons pas de modeleur ni d’animateur actif et cela nous freine beaucoup, vous pouvez nous rejoindre.
Le nouveau chaingun d’extreazz.
La painsaw produit désormais des étincelles quand elle impacte des surfaces dures, agissant comme le Grand Communicateur de vos désirs de disperser des tripes extra-terrestres.
La nouvelle painsaw d’Alex Tikkoiev.
Il y a dix ans nous avons reçu une fonctionnalité bien sympathique appelée particules douces (soft particles). Cela empêche certains effets comme le brouillard ou les nuages d’acides d’être affichés de manière disgracieuse lorsqu’ils touchent des murs. Initialement l’effet n’était configuré que pour une poignée de shaders. Rapidement des programmeurs paresseux se sont dits : « configurer les shaders est ennuyeux, et si nous activions la fonctionnalité pour toutes les particules ? ». Malheureusement, cela rend certaines particules invisibles, spécialement les effets d’impacts qui sont très proches de murs ou de sols. Apparemment personne n’a remarqué ça pendant 9 ans, jusqu’à ce que nous retournions à la configuration manuelle de shaders à cause de changements architecturaux liés à autosprite2. Après une revue méticuleuse de tous les systèmes de particules du jeu, nous avons corrigé, retiré ou amélioré certains effets graphiques. Par exemple le souffle du canon lucifer produit désormais une onde de choc, causant une distorsion visuelle. Un tel effet était déjà présent dans les données, mais il ne fonctionnait pas à cause d’un problème de tri des shaders. Le tir secondaire produit aussi un flash violacé à l’impact, effet qui était souvent invisible à cause des particules douces automatiques.
Le nouvel effet de soin de la médistation.
Reaper a repensé l’effet de soin de la medistation et l’a rendue plus transparente, pour que les joueurs en cours de soin puissent voir à travers.
Sweet a ajouté un nouvel effet visuel au champ de force de la carte plat23. Cela utilise l’effet de mirage de chaleur (heat haze) qui était initialement conçu pour les armes et les effets de feu, mais il se trouve que ça peut également produire des effets très sympathiques dans les cartes. Nous remercions Masmblr pour la manière dont il nous fait avancer en démontrant dans ses propres cartes communautaires comment il est possible d’exploiter de façon créative et nouvelle des fonctionnalités que nous proposons déjà !
Fichier d’entitéLe moteur prend désormais en charge les fichiers d’entité. Cela est particulièrement utile pour les cartes (niveaux de jeu) sans source (il y en a des centaines !). Un fichier d’entité permet certaines personnalisations de comment certaines entités fonctionnent (portes, ascenseurs, téléporteurs…). Il est possible d’extraire une description d’entités avec q3map2 et le fichier extrait peut être édité avec un éditeur de texte et lu par le moteur lorsqu’il charge une carte. Le fichier d’entité peut aussi être utilisé pour modifier comment la lumière d’une carte sera appliquée (il est possible d’y renseigner des variables qui configurent le moteur de rendu pour cette carte).
Le futur est lumineuxUne vidéo démontrant la compatibilité des lumières de diverses cartes historiques (voir la vidéo complète).
Un effort aux long cours est fait pour que le moteur affiche de meilleures lumières en jeu. Les investigations ont commencé à livrer des résultats significatifs en 2020 avec l’affinage du procédé de compilation des lumières. Cet effort est multi-facettes et touche à de multiples aspects de la chaîne de production et de rendu. Ces dernières années, Illwieckz s’est assuré que différents types d’éclairage soient pris en charge. L’éclairage par vertex (vertex lighting) a été ajouté en plus de l’éclairage par grille (grid lighting) et de l’éclairage par texture (lightmap). Ainsi les cartes qui mélangent éclairage par vertex et éclairage par texture sont désormais correctement affichées. Illwieckz a aussi débuggué les styles de lumières, une sorte de lumière dynamique pré-calculée qui fusionne plusieurs textures de lumière (lightmap) au moment du rendu.
Comparaison entre l'ancien suréclairage (à gauche) et le nouveau suréclairage (à droite). Comparer avec un curseur.
Après cela Illwieckz a réimplémenté le mécanisme de suréclairage (overbright) pour éviter la troncature des lumières (light clamping). Il se trouve que le moteur de rendu de Quake 3 souffrait d’une limitation qui atténuait les lumières autant qu’il les éclaircissait… Le nouveau code non-buggé est désormais activé par défaut. Cela a suscité des débats puisque comme le moteur id Tech 3 avait un suréclairage buggé depuis plus de 20 ans, utiliser un moteur de rendu non-buggé peut révéler des bugs que les créateurs de niveaux n’ont jamais vu avant, et il était même possible d’introduire des bugs dans certains logiciels de production sans que les gens ne s’en rendent compte ! Certaines personnes peuvent argumenter que l’affichage buggé est la façon dont le créateur du niveau s’attend à ce que son niveau soit vu… Cette histoire va si loin que cela mériterait un article dédié !
La prochaine étape sur ce chemin vers un meilleur éclairage sera de faire de la colorimétrie correctement et de faire de la fusion linéaire de lumière (quelque chose qu’id Tech 3 n’a jamais fait), mais cette tâche est pour le futur.
Corrections du moteur de renduUne vidéo montrant la récursion de miroirs et de portails et leur fusion (voir la vidéo complète).
- Sprites : Les surfaces utilisant le mot clé de shader autosprite2 sont correctement affichées, c’est parfois utilisé pour afficher des effets de symétrie axiale, par exemple pour une flamme de bougie. Ce travail a été réalisé par Slipher.
- Portails et miroirs : Reaper a terminé l’implémentation de la récursion de portail et de miroir, a implémenté la fusion de portails et la fusion alphaGen (une technique qui permet d’obscurcir un portail selon la distance à celui-ci), et a rendu possible d’avoir des portails mobiles. Il a corrigé la rotation de portail ainsi que des bugs de portails liés aux lumières, et s’est assuré que du creep extra-terrestre de taille 10 millions de fois la taille de l’univers observable n’apparaissent pas dans les portails…
- Vidéo : Nous pouvons à nouveau jouer des vidéos sur les surfaces. Avec le temps le code s’était gâté (rotten code), était devenu cassé et avait même été enlevé tandis qu’il était cassé. Il fut ressuscité et a fait l’objet d’une profonde réécriture par Slipher, et la fonctionnalité fonctionne de nouveau — et même mieux qu’avant (avec moins de limites arbitraires) ! Cette nouvelle implémentation était déjà visible dans la version 0.54.1, la voici désormais dans une version majeure. Le seul format pris en charge est l’antique format RoQ utilisé par Quake 3 qui, par mesure de compatibilité avec les données de jeu existantes, est le codec que nous devons prendre en charge avant tout autre codec. Nous ne fermons pas la porte au fait de prendre en charge d’autres codecs, mais pour cela il faudrait que la fonctionnalité soit utilisée plus souvent pour justifier cet effort supplémentaire.
- Brouillard : Reaper a corrigé l’effet de brouillard, qui était cassé dans la version 0.45. Oups !
- Lumières : Les lumières dynamiques sont désormais moins pixelisées, quand bien même ce problème n’est pas encore complètement corrigé.
- PBR : La prise en charge de textures prétendues « basées sur la physique » est désormais dans un état viable grâce à Ishq (plus d’artefacts noirs). C’est déjà utilisé avec un nouveau modèle de chaingun. Pour le rendre bon, nous avons besoin de le faire fonctionner avec les réflexions spéculaires (réflexions statiques).
Une vidéo montrant la lecture de vidéo sur les surfaces du jeu (voir la vidéo complète).
En corrigeant le shader autosprite2, la fusion de portails et la lecture de vidéos, nous avons corrigé 3 régressions du moteur original de Quake 3 et qui étaient liées à la prise en charge de format de fichiers anciens et de techniques tout aussi anciennes. Parce que notre moteur de rendu n’est plus celui de Quake 3, corriger certaines de ces régressions requiert parfois d’écrire du code neuf plutôt que de corriger un code existant, et c’est exactement ce qui s’est produit pour les portails.
Performance amélioréesUnvanquished 0.55.2 a été publiée pour Noël !
Le moteur et le jeu sont plus rapides que jamais !
- Simplification du ciel : Reaper a purifié par le feu le code de rendu du ciel qui était archaïque et… étrange. Ce code pouvait générer plus de 1000 triangles par trame rien que pour dessiner le ciel. Une skybox n’a pas besoin d’une géométrie aussi fine, elle est simplement modélisée comme l’intérieur d’un cube. En plus le code faisait des allers-retours mémoire entre la mémoire principale et la mémoire graphique…
Une intelligence artificielle libre est-elle possible ?
Ces derniers temps, on a beaucoup parlé d’intelligence artificielle sur LinuxFr.org. D’IA propriétaires, et d’IA libres. Mais peut-on vraiment faire une IA libre ? La notion n’est pas sans poser quelques difficultés. Une (pas si) courte discussion du problème.
- On appellera IA un réseau de neurones artificiels
- Pour comprendre le réseau de neurones, il est nécessaire de disposer de bases statistiques
- Le réseau de neurones
- Le but du logiciel libre est de rendre le pouvoir à l’utilisateur
-
Le réseau de neurones est difficilement compatible avec le libre
- Personne ne sait vraiment ce que fait un réseau de neurones
- Disposer de la description complète d’un réseau de neurones ne permet pas de l’améliorer
- La définition du code source d’un réseau de neurones est ambiguë
- Cette ambiguïté fait courir un risque juridique sous certaines licences libres
- La définition d’une IA open source ressemble furieusement à un constat d’échec
- Conclusion : qu’attendre d’une IA libre ?
Commençons par définir notre objet d’étude : qu’est-ce qu’une IA ? Par « intelligence artificielle », on pourrait entendre tout dispositif capable de faire réaliser par un ordinateur une opération réputée requérir une tâche cognitive. Dans cette acception, un système expert qui prend des décisions médicales en implémentant les recommandations d’une société savante est une IA. Le pilote automatique d’un avion de ligne est une IA.
Cependant, ce n’est pas la définition la plus couramment employée ces derniers temps. Une IA a battu Lee Sedol au go, mais ça fait des années que des ordinateurs battent les humains aux échecs et personne ne prétend que c’est une IA. Des IA sont employées pour reconnaître des images alors que reconnaître un chien nous semble absolument élémentaire, mais l’algorithme de Youtube qui te suggère des vidéos pouvant te plaire parmi les milliards hébergées fait preuve d’une certaine intelligence et personne ne l’appelle IA. Il semble donc que le terme « IA » s’applique donc à une technique pour effectuer une tâche plus qu’à la tâche en elle-même, ou plutôt à un ensemble de techniques partageant un point commun : le réseau de neurones artificiels.
Dans la suite de cette dépêche, j’utiliserai donc indifféremment les termes d’IA et de réseau de neurones1.
Pour comprendre le réseau de neurones, il est nécessaire de disposer de bases statistiquesLes statistiques (ou la statistique, on peut dire les deux, comme en Alexandrie), c’est la branche des mathématiques qui s’intéresse aux moyens, à partir de données observées et fondamentalement probabilistes, d’en tirer des conclusions généralisables (et idéalement, de prédire l’avenir à partir du passé).
La data science, c’est la branche de l’informatique qui s’intéresse aux moyens, à partir de données emmagasinées sur lesquelles on ne fait pas d’hypothèse de mode de génération, d’en tirer des conclusions généralisables (et idéalement, de prédire les données futures).
Ça vous semble similaire ? Ça l’est. Les deux champs vont avoir des divergences de vocabulaire, de langages (les stateux préfèreront R, les data scientists Python), de formation (les stateux sont plutôt des universitaires, les data scientists plutôt des informaticiens au niveau licence, mais ils ont les mêmes masters et doctorats), mais fondamentalement, et surtout mathématiquement, c’est la même chose. Les connaissances en inférence statistique (notamment bayésienne, pour ceux à qui ça parle) se généralisent très bien à la data science.
Pour faire court, un statisticien est un data scientist qui se la pète, alors qu’un data scientist est un informaticien qui, n’étant pas assez bon pour survivre à la rude concurrence universitaire, a multiplié son salaire par 10 ou 20 en allant vendre ses compétences statistiques à Facebook.
Les statistiques reposent sur la modélisationEn statistique, la manière la plus courante de répondre à une question est de construire un modèle. Prenons une question simple : je dispose d’un jeu de données où j’ai enregistré, pour 1000 personnes, leur IMC et leur taux de cholestérol. Je souhaite savoir s’il y a un lien entre les deux. On souhaiterait, dans ce cas simple, rechercher une relation monotone, sans faire d’hypothèse sur le type de relation.
Un exemple : la régression linéaireUne manière de répondre à ma question est d’écrire et de trouver les meilleurs A et B pour que la droite « colle » le mieux possible au nuage de points. On démontre que la meilleure droite est celle qui minimise un certain critère, la somme des carrés des erreurs. Une fois qu’on a la meilleure droite possible, on peut faire plein de choses avec :
- On peut rétro-prédire le taux de cholestérol des personnes déjà observées et voir de combien la prédiction s’écarte du réel, ce qui fournit une erreur moyenne de prédiction ;
- On peut faire de même en prédisant juste le taux de cholestérol moyen pour tous les individus et comparer les erreurs moyennes de prédiction, ce qui permet de voir de combien le modèle améliore la prédiction (et donc de quantifier la quantité d’info apportée par la donnée IMC sur la variable cholestérol) ;
- On peut étudier le signe de A : si A est négatif, prendre du poids fait baisser le cholestérol : si A est positif, prendre du poids augmente le cholestérol : si A est nul, le poids n’apporte pas d’info sur le cholestérol.
- Par contre, on ne peut rien dire de la causalité. Tout ce qu’on a observé, ce sont des personnes qui, au même moment, avaient un IMC et un taux de cholestérol donnés. Impossible de dire s’ils ont ce cholestérol parce qu’ils ont cet IMC, s’ils ont cet IMC parce qu’ils ont ce cholestérol, ou s’ils ont ce cholestérol et cet IMC parce qu’ils ont une troisième exposition.
- On peut enfin faire effectuer de la prédiction à notre modèle : en lui passant une personne dont on ne connaît que l’IMC, on peut estimer son taux de cholestérol et assortir cette prédiction d’un niveau de certitude (ça demande un peu plus de maths, mais c’est l’idée).
On peut vouloir ajouter une troisième variable, mettons le tabagisme. On écrira alors :
Avec la variable tabac codée à 0 (non fumeur) ou 1 (fumeur). Noter que notre modèle est alors passé en dimension 3 : on ne cherche plus à faire passer la meilleure droite par rapport au nuage de points en 2D, mais à faire passer le meilleur plan par rapport au nuage de points en 3D. Noter aussi qu’on peut facilement inclure des variables qualitatives : il suffit de les coder 0 ou 1. On peut d’ailleurs inclure des variables à n modalités : il suffit de les recoder en n-1 sous-variables en 0-1 (la modalité de référence étant celle pour laquelle toutes les sous-variables sont à 0).
Les sont appelés des paramètres : c’est en les faisant varier qu’on ajuste le modèle aux données.
On peut ainsi ajouter un nombre quelconque de variables… Ou peut-être pas. En effet, on va finir par atteindre un seuil où le meilleur hyperplan est tout simplement celui qui passe par tous les points ! Si j’ai 50 individus et 50 paramètres, il est facile de choisir un plan qui passe par tous les individus. C’est ce qu’on appelle le surapprentissage : le modèle a tout simplement appris le jeu de données par cœur ! Le surapprentissage est un écueil des modèles trop complexes et un réseau de neurones est tout à fait capable de surapprendre.
Le réseau de neurones Le neurone naturelLes neurones sont les cellules du système nerveux. Elles sont spécialisées dans la transmission d’information.
Comme tu peux le voir sur cette image issue de Wikimedia (source), un neurone comprend un nombre quelconque de dendrites, un corps cellulaire, et un axone. Point crucial : l’axone est unique. Il peut lui-même transmettre de l’information à différents neurones en aval, mais il transmet la même information. Or l’information, dans un neurone, peut entrer par les dendrites et par le corps cellulaire, mais elle ne peut ressortir que par l’axone (on peut faire abstraction de la gaine de myéline et des nœuds de Ranvier, qui ont un rôle central dans la vitesse de conduction de l’information mais qui ne changent rien aux calculs effectués). Autrement dit, un neurone transmet la même information à tous les neurones d’aval, et si ceux-ci en font un usage différent, c’est uniquement lié à leurs propres calculs en interne.
Le neurone formelOn peut modéliser un neurone, par analogie avec le neurone naturel. Notre neurone formel pourra donc prendre un nombre quelconque d’entrées, mais comme un neurone naturel, il ne produira qu’une seule sortie. Notre neurone est donc une fonction de ses entrées :
En pratique (mais ça n’a rien d’obligatoire), on prend souvent une fonction d’une combinaison linéaire des entrées :
Avec une contrainte : la fonction (qu’on appelle fonction d’activation) doit être monotone (idéalement strictement monotone), dérivable presque partout (c’est nécessaire à l’optimisation du réseau, qu’on verra plus tard), définie sur un intervalle suffisamment large pour qu’on soit toujours dedans, et non linéaire (sinon mettre les neurones en réseau n’a aucun intérêt, autant faire directement une unique régression linéaire).
En pratique, on prend donc quelques fonctions classiques :
- La fonction binaire : si , sinon
- La fonction logistique, une amélioration de la fonction binaire : . Avantage : elle est strictement monotone, dérivable partout, et elle prend quand même ses valeurs entre 0 et 1.
- La fonction Rectified Linear Unit (ReLU, qu’on peut prononcer « relou ») : si , sinon. Avantage : elle est très facile (donc rapide) à calculer et à dériver. On peut la rendre strictement monotone en la modifiant à la marge : si , sinon, avec .
Tout l’intérêt du neurone formel réside dans sa mise en réseau. Un unique neurone ne fait pas mieux qu’une régression linéaire. On construit donc un réseau de neurones. Pour ce faire, on va donc générer plusieurs neurones, chacun prenant en entrée la sortie de plusieurs neurones et produisant une sortie unique, qui sera à son tour utilisée en entrée par d’autres neurones. On ajoute un ensemble de neurones qu’on pourrait qualifier de « sensitifs », au sens où ils prennent en entrée non pas la sortie d’un neurone antérieur, mais directement l’input de l’utilisateur, ou plutôt une partie de l’input : un pixel, un mot… Enfin, une sortie est ajoutée : elle produit le résultat final.
Étant donné que les neurones sont virtuels et n’ont pas d’emplacement géographique, il est assez logique de les représenter en couches : la couche 0 est constituée des neurones sensitifs, la couche 1 prend en entrée les résultats de la couche 0, et ainsi de suite. Classiquement, tous les neurones de la couche n+1 prennent en entrée les sorties de tous les neurones de la couche n.
Se pose alors la question : combien de neurones par couche, et combien de couches au total ?
On peut considérer deux types de topologies : soit il y a plus de neurones par couche que de couches : le réseau est plus large que long, on parlera de réseau large. Soit il y a plus de couches que de neurones par couche, auquel cas le réseau est plus long que large, mais on ne va pas parler de réseau long parce que ça pourrait se comprendre « réseau lent ». On parlera de réseau profond. C’est de là que viennent les Deep et les Large qu’on voit un peu partout dans le marketing des IA. Un Large Language Model, c’est un modèle, au sens statistique, de langage large, autrement dit un réseau de neurones avec plus de neurones par couche que de couches, entraîné à traiter du langage naturel. On constate empiriquement que certaines topologies de réseau sont plus efficaces pour certaines tâches. Par exemple, à nombre de neurones constant, un modèle large fera mieux pour du langage. À l’inverse, un modèle profond fera mieux pour de la reconnaissance d’images.
Un résultat théorique important est que les réseaux de neurones sont Turing-complets. C’est-à-dire que, pour tout programme que l’on peut coder et qui sorte une réponse algorithmique, il existe un réseau de neurones qui donne le même résultat. La réciproque est vraie aussi : ce qui est faisable avec un réseau de neurones est faisable en C ou dans un autre langage, au pire en recodant le réseau dans ce langage.
Le réseau de neurones présente un effet boîte noire importantPrenons maintenant un élément d’information et essayons de suivre son trajet dans le modèle jusqu’à la sortie. Dans une régression linéaire, c’est assez facile : le poids de l’IMC va peser pour dans le résultat final. Dans une forêt aléatoire, on peut toujours isoler les arbres où apparaît une donnée et essayer de regarder combien elle pèse. C’est fastidieux mais ça reste faisable. Dans un réseau de neurones, c’est impossible. Chaque neurone de la couche 1 va passer un résultat agrégé à la couche 2, où chaque donnée de la couche 0 ne compte plus que comme partie d’un tout. De même, chaque neurone de la couche 2 va agréger tous les résultats de la couche 1. Il devient impossible d’individualiser l’effet d’une donnée ou même celui d’un neurone.
Ainsi, même si je connais l’intégralité du contenu du modèle, il m’est impossible de donner du sens à une partie du modèle, prise isolément. Le modèle se comporte comme un bloc monolithique, et la seule manière d’étudier un nouvel exemple est de lui appliquer tout le modèle et de voir ce qui sort. C’est ce qu’on nomme l’effet boîte noire.
Attention : l’effet boîte noire n’est pas lié au nombre de paramètres du modèle. Si je fais de la génétique, et que j’étudie 2000 mutations génétiques individuelles (des SNP, pour single nucleotide polymorphism), je peux assez facilement ajuster un modèle de régression logistique (qui est une variante de la régression linéaire où on fait prédire non pas une variable quantitative, mais une probabilité) à 2000 paramètres (un pour chaque SNP). Chaque paramètre sera parfaitement compréhensible et il n’y aura pas d’effet boîte noire.
Il n’est pas non plus lié à ta méconnaissance des mathématiques, cher lectorat. Des statisticiens chevronnés se cassent les dents sur l’effet boîte noire. Il est intégralement lié à la structure du modèle. Certains types de modèles en ont, d’autres n’en ont pas. Les réseaux de neurones en ont.
Cet effet a une conséquence perturbante : même si on sait ce que fait un réseau de neurones, il est impossible de savoir comment il le fait ! On pourrait argumenter que ce n’est pas forcément différent de ce que nous faisons : si on montre à un enfant de 3 ans une photo de chien, il saura dire que c’est un chien, mais il ne saura pas dire pourquoi c’est un chien. Cependant, on demande rarement à un programme d’être réflexif, mais on demande toujours à son auteur de savoir comment il tourne. C’est un peu la base de la programmation.
Le réseau de neurones est un modèle statistiqueReprenons : on a un paradigme (le réseau de neurones) capable d’effectuer n’importe quelle tâche pour laquelle il existe une solution algorithmique, à condition de le programmer correctement… Mais on ne sait pas le programmer ! Heureusement, il existe un contournement : on ne va pas le programmer, on va l’ajuster, comme un modèle statistique. Ou l’entraîner, si on préfère le terme de « machine learning ».
Tu t’en souviens, cher lecteur, un réseau de neurones est un ensemble de fonctions dont chacune prend en entrée différentes données avec des coefficients (les fameux ). On va commencer par initialiser l’apprentissage en donnant des valeurs aléatoires à ces coefficients. Ensuite, on va soumettre à notre réseau de neurones des tas et des tas de données correctes, et qu’on va comparer ce qu’il prédit à ce qu’on attend. La différence s’appelle l’erreur. Et à chaque itération, on va identifier les neurones les plus générateurs d’erreur et les pénaliser (réduire leur poids, ou plutôt réduire leur poids dans les neurones où c’est nécessaire), tout en favorisant les meilleurs neurones. Les détails de la technique (qui s’appelle la rétropropagation de l’erreur) dépassent largement le cadre de cette courte introduction, mais l’essentiel est qu’à la fin, on obtient un réseau capable de donner des réponses proches de ce qui existait dans l’ensemble des données correctes qu’on lui a passé et de généraliser quand la demande est différente d’une donnée de l’ensemble d’apprentissage. Avantage : en pratique, un réseau de neurones est capable de prendre en entrée n’importe quel type de structure de données : image, texte, son… Tant que les neurones d’entrée sont adaptés et qu’il existe un ensemble d’apprentissage suffisamment grand, c’est bon.
Tous les modèles sont faux, certains sont utiles, et c’est vrai aussi pour le réseau de neuronesBien sûr, il y a des limites. La première est la complexité algorithmique. Un réseau de neurones nécessite de réaliser un nombre astronomique d’opérations simples : pour chaque couche, il faut, pour chaque neurone, calculer la somme des produits des coefficients avec toutes les sorties de la couche antérieure, soit multiplications, où n est le nombre de neurones par couche et c le nombre de couches. Par exemple, pour un petit réseau de 10 couches de 20 neurones, plus une couche d’entrée, on réaliserait à chaque itération multiplications en virgule flottante, et encore, c’est ici un tout petit réseau : un réseau comme ChatGPT a des neurones qui se comptent par millions, voire dizaines de millions !
Une autre limite est la précision des réponses. Le réseau de neurones étant un modèle statistique, il n’est capable que d’interpoler, c’est-à-dire trouver une réponse à partir de cas similaires. Cette interpolation est rarement aussi précise que celle que donnerait une réponse formelle si elle existait : si Newton avait eu accès à des réseaux de neurones, nous aurions une prédiction du mouvement des planètes qui ne baserait sur aucune théorie, qui serait à peu près exacte mais insuffisamment précise pour envoyer des sondes sur Mars. Quant à s’interroger sur la précession du périhélie de Mercure, on oublie.
De manière générale, on peut s’interroger sur ce qui amène un réseau de neurones à se planter. On peut diviser les erreurs en plusieurs catégories :
- La question posée n’a aucun rapport avec les données passées en entrée. Par exemple : « Sachant que la dernière personne que j’ai croisée dans la rue avait 42 ans, indique-moi son genre ». Le modèle n’a pas assez d’information pour répondre.
- La question posée n’a aucun rapport avec l’ensemble d’apprentissage. Par exemple, demander à un modèle entraîné à reconnaître des photos de chien de reconnaître une voiture. En général, ce problème est résolu en contraignant le format des questions ; dans cet exemple, il suffirait de ne pas permettre à l’utilisateur de poser une question, juste de poster une photo et de recevoir une réponse. D’ailleurs, on ne voit pas très bien pourquoi entraîner un tel modèle à traiter du langage.
- L’ensemble d’apprentissage est trop restreint/biaisé. L’exemple typique est le modèle qui prétendait reconnaître les délinquants à une simple photo et identifiait en fait tous les noirs : ben oui, ils étaient majoritaires dans les délinquants de l’ensemble d’apprentissage. Noter qu’il existe des problèmes où l’ensemble d’apprentissage sera toujours trop restreint pour un certain niveau de précision exigé. Si on demande à un réseau de dire si un point donné est à l’intérieur ou à l’extérieur d’un flocon de Koch, il va falloir lui passer une infinité de données d’apprentissage pour qu’il apprenne les cas limites juste par interpolation (alors qu’avec un modèle formel, ça serait assez facile).
- Le modèle est parasité par une donnée annexe : c’est une problématique assez spécifique du réseau de neurones. L’exemple le plus classique est celui des images de mains : après tout, le voisin le plus probable d’un doigt, c’est un autre doigt. L’amusant, c’est que ce problème serait résolu assez facilement en demandant au modèle de compter 4 doigts et un pouce. Mais comme on ne peut pas programmer directement un réseau de neurones…
- Enfin, si les motifs précédents ont été écartés, je dois me demander si mon modèle n’est pas inadapté : soit qu’il n’a pas assez de neurones, soit que la topologie n’est pas bonne. Plus de neurones permettent de traiter des données plus complexes et leur disposition permet d’augmenter leur efficacité.
En définitive, on peut voir le réseau de neurones comme un outil qui résout approximativement un problème mal posé. S’il existe une solution formelle, et qu’on sait la coder en un temps acceptable, il faut le faire. Sinon, le réseau de neurones fera un taf acceptable.
Le but du logiciel libre est de rendre le pouvoir à l’utilisateurOn a beaucoup glosé, et on continuera de le faire longtemps, sur la philosophie du Libre. Free Software Foundation d’un côté, Open Source Initiative de l’autre, les sujets de discorde ne manquent pas. Mais il faut au moins créditer l’OSI sur un point : avoir clarifié le fait que le Libre est avant tout un mouvement politique, au sens noble du terme : il vise à peser sur la vie de la cité, alors que l’Open Source vise avant tout à disposer de logiciels de qualité.
La première des libertés est celle de savoir ce que je faisÇa paraît évident dans la vie de tous les jours : je sais ce que je fais. Si je décide de prendre une pelle et de planter un arbre dans mon jardin, je sais que je suis en train de prendre une pelle et de planter un arbre dans mon jardin. Si je décide de prendre un couteau et de le planter dans le thorax de mon voisin, je sais ce que je fais. C’est une liberté fondamentale, au sens où elle fonde toutes les autres. Si je ne sais pas ce que je fais, je ne peux signer un contrat, par exemple (c’est d’ailleurs le principe qui sous-tend le régime de la tutelle en droit). D’ailleurs, comme toute liberté, elle fonde une responsabilité. Si je ne savais pas ce que je faisais (et que je peux le prouver), je peux plaider l’abolition du discernement et échapper à ma responsabilité pénale, quelle que soit l’infraction commise, même les plus graves2
Dans la vie de tous les jours, donc, il est évident que je sais ce que je fais. Mais avec un ordinateur, c’est beaucoup moins évident. Quand j’exécute Windows, je ne sais pas ce que je fais. Pas seulement parce que je ne connais pas la séquence de boot, mais de façon beaucoup plus fondamentale : parce que n’ayant pas accès au code source, je ne sais pas ce que fait le programme que j’exécute. Ce qui pose un problème majeur de confiance dans le logiciel exécuté :
- Confiance dans le fait que le programme fait bien ce que son programmeur a voulu qu’il fasse (absence de bugs)
- Confiance dans le fait que le programmeur avait bien mon intérêt en tête et pas seulement le sien (sincérité du programmeur, fréquemment prise en défaut dans le logiciel non libre)
Dans le système des 4 libertés du logiciel libre, cette liberté est la liberté 1. Elle passe après la liberté 0 (liberté d’exécuter le programme) et avant la liberté 2 (liberté de redistribuer le programme). On pourrait légitimement discuter de sa priorité par rapport à la liberté 0 (est-il raisonnable d’exécuter un programme dont on ne sait pas ce qu’il fait ?) mais ça dépasserait l’objet de cette dépêche.
Si je sais ce que je fais, je dois pouvoir modifier ce que je faisConséquence logique de la liberté précédente : si je n’aime pas ce que fait un programme, je dois pouvoir l’améliorer. Si je ne sais pas le faire moi-même, je dois pouvoir payer quelqu’un pour l’améliorer. Là encore, ça suppose l’accès au code source, ne serait-ce que pour savoir ce que fait le programme. Il s’agit de la liberté 3 du logiciel libre.
Le réseau de neurones est difficilement compatible avec le libre Personne ne sait vraiment ce que fait un réseau de neuronesOn l’a vu, les réseaux de neurones présentent un effet boîte noire important. Déjà, la plupart des IA commerciales ne sont accessibles qu’au travers d’une interface ou une API. Elles n’exposent que rarement les neurones. Mais même pour une personne disposant de tous les neurones, autrement dit de la description complète du réseau, l’effet boîte noire est tel que le fonctionnement du réseau de neurones est inintelligible. D’ailleurs, s’il était intelligible, il serait très vite simplifié !
En effet, on peut recoder tout réseau de neurones dans un langage plus rapide, dès lors qu’on comprend ce qu’il fait (puisqu’il est Turing-complet). Vu la consommation astronomique d’énergie des réseaux de neurones, s’il existait un moyen de comprendre ce que fait un réseau de neurones et de le traduire dans un autre langage, on le ferait très vite. Ce qui fournirait d’ailleurs des réponses à des questions théoriques ouvertes comme : qu’est-ce que comprendre une phrase ? Comment reconnaît-on un chien, un visage, un avion ?
Disposer de la description complète d’un réseau de neurones ne permet pas de l’améliorerOn l’a vu : si je dispose de la totalité des neurones, je dispose de la totalité de la description du réseau de neurones. Mais comme je suis incapable de savoir ce qu’il fait, je ne suis pas plus avancé pour l’améliorer, qu’il s’agisse de retirer un défaut ou d’ajouter une fonctionnalité. Noter d’ailleurs que ceci n’est pas forcément impactant de la même manière pour tous les aspects du réseau de neurones : si je n’ai aucun moyen d’être sûr de l’absence de bugs (c’est même le contraire ! Il y a forcément des bugs, c’est juste que je ne les ai pas trouvés ou qu’ils ne sont pas corrigeables), j’ai en revanche peu d’inquiétude à avoir concernant la sincérité du programmeur : comme lui non plus ne maîtrise pas sa bestiole, pas de risque qu’il soit insincère3.
La définition du code source d’un réseau de neurones est ambiguëPosons-nous un instant la question : qu’est-ce que le code source d’un réseau de neurones ? Est-ce la liste des neurones ? Comme on l’a vu, ils ne permettent ni de comprendre ce que fait le réseau, ni de le modifier. Ce sont donc de mauvais candidats. La GPL fournit une définition : le code source est la forme de l’œuvre privilégiée pour effectuer des modifications. Dans cette acception, le code source d’un réseau de neurones serait l’algorithme d’entraînement, le réseau de neurones de départ et le corpus sur lequel le réseau a été entraîné.
Cette ambiguïté fait courir un risque juridique sous certaines licences libresTu devines alors, cher lecteur, là où je veux en venir… Si le corpus comprend des œuvres non libres, tu n’as tout simplement pas le droit de le diffuser sous une licence libre ! Et si tu t’es limité à des œuvres libres pour entraîner ton modèle, tu risques fort d’avoir un ensemble d’apprentissage trop restreint, donc un réseau de neurones sans intérêt.
Alors il y a quatre moyens de tricher.
Le premier, c’est de t’asseoir sur la GPL et de considérer qu’en distribuant les neurones, tu as fait le taf. La ficelle est grossière. Je viens de passer une dépêche à te démontrer que c’est faux, tu pourrais au moins me montrer un peu plus de respect.
Le deuxième, c’est de distribuer sous une licence non copyleft, genre BSD ou WTFPL. Une licence qui ne nécessite pas de distribuer le code source. Certes, mais en fait tu ne fais pas du Libre.
Le troisième, c’est de considérer le réseau de neurones comme une donnée, pas un exécutable. Donc pas de code source. La partie sous GPL serait alors l’interface graphique, et le réseau, une donnée. C’est assez limite. Une donnée exécutable, ça s’approche dangereusement d’un blob binaire.
Le quatrième, c’est de repenser complètement le paradigme du logiciel libre et de considérer qu’il vise avant tout à rééquilibrer les rapports de pouvoir entre programmeur et utilisateur, et qu’en redistribuant les neurones, tu as fait le job. Sur les rapports de pouvoir, tu n’as pas tort ! Mais d’une part, ça ne tiendra pas la route devant un tribunal. D’autre part, il persiste une asymétrie de pouvoir : tu as accès au corpus, pas l’utilisateur.
Quand bien même on admettrait que le code source est l’ensemble corpus + algorithme d’optimisation + réseau de neurones de départ, l’optimisation d’un réseau de neurones consomme autrement plus de ressources que la compilation d’un programme plus classique, des ressources qui sont loin d’être à la portée du quidam classique. À quoi servirait un code source impossible à compiler ?
Enfin, même cette définition du code source pose problème : elle n’est en fait pas beaucoup plus lisible que le réseau lui-même. Ce n’est pas parce que j’ai accès aux centaines (de milliers) de textes sur lesquels un réseau a été entraîné que je peux prédire comment il va se comporter face à une nouvelle question.
Comment les boîtes qui font de l’IA non libre résolvent-elles ce dilemme ? Elles ne le résolvent pasC’est presque enfoncer une porte ouverte que dire que l’IA pose de nombreuses questions de droit d’auteur, y compris dans le petit microcosme du non-libre. Cependant, les IA non-libres ont un avantage sur ce point : si le réseau de neurones ne permet pas de remonter au corpus initial (donc en l’absence de surapprentissage), alors elles peuvent tranquillement nier avoir plagié une œuvre donnée. Tu ne me verras pas défendre les pauvres auteurs spoliés, car j’ai toujours considéré que la nature même de l’information est de circuler sans barrières (Information wants to be free, tout ça) et que le droit d’auteur en est une, et particulièrement perverse.
La définition d’une IA open source ressemble furieusement à un constat d’échecL’OSI a publié une définition d’IA open source. Cette définition mérite qu’on s’y attarde.
Premier point intéressant : après des années à tenter de se démarquer du Libre, notamment via la définition de l’Open Source qui tente de reformuler les 4 libertés sans recopier les 4 libertérs, l’OSI baisse les bras : est open source une IA qui respecte les 4 libertés.
Deuxième point intéressant : est open source une IA qui publie la liste des neurones, le corpus d’entraînement et la méthode d’entraînement. En fait, ça revient à ne pas choisir entre les neurones et leur méthode d’entraînement. Soit, mais ça ne résout pas le problème de l’effet boîte noire. Au mieux, ça revient à admettre qu’il est le même pour le programmeur et l’utilisateur.
Conclusion : qu’attendre d’une IA libre ?Il ne fait aucun doute que développer des IA libres exigera de nouvelles licences. La GPL, on l’a vu, expose à un risque juridique du fait de l’ambiguïté de la définition du code source.
Il est à noter, d’ailleurs, qu’une IA repose rarement exclusivement sur son réseau de neurones : il y a systématiquement au moins un logiciel classique pour recueillir les inputs de l’utilisateur et les passer au réseau de neurones, et un second en sortie pour présenter les outputs. Ces briques logicielles, elles, peuvent tout à fait suivre le paradigme classique du logiciel libre.
En définitive, cher lecteur qui ne développes pas d’IA, je t’invite surtout à te demander : qu’attends-tu d’une IA ? Qu’entends-tu quand on te parle d’IA libre ? Plus fondamentalement, l’IA serait-elle un des rares domaines où il existe une distinction pratique entre libre et Open Source ?
Il n’y a pas de façon simple de faire une IA libre, il n’y a peut-être pas de façon du tout. Mais le principe du libre, c’est que c’est à l’utilisateur in fine de prendre ses décisions, et les responsabilités qui vont avec. Je n’espère pas t’avoir fait changer d’avis : j’espère modestement t’avoir fourni quelques clés pour enrichir ta réflexion sur le sens à donner au vocable IA open source qu’on voit fleurir ici et là.
-
Et je mettrai « artificiel » à la poubelle parce que Implicit is better than explicit, rien que pour embêter Guido). ↩
-
Bon, certaines infractions complexes à exécuter, comme le trafic de drogue ou le génocide, requièrent une certaine implication intellectuelle et sont donc peu compatibles avec l’altération du discernement, mais c’est lié au fait que l’infraction elle-même requiert un certain discernement. ↩
-
Du moins au niveau du réseau de neurones lui-même. Les entrées et les sorties peuvent tout à fait passer par une moulinette insincère et codée dans un langage tout à fait classique. ↩
Commentaires : voir le flux Atom ouvrir dans le navigateur
Réviser SQL en jouant au détective : SQLNoir
SQL Noir est un jeu libre (licence MIT) par Hristo « Cool as a cucumber » Bogoev, où vous incarnerez le rôle d’une personne enquêtant sur un crime, mais à grand renfort de requêtes SQL. Le SQL pour Structured Query Language ou « langage de requêtes structurées » est un langage informatique normalisé servant à exploiter des bases de données relationnelles (Wikipédia).
Bref vous avez une interface web qui vous permet de faire des requêtes dans les bases de données de témoins, suspects, enregistrements audio ou vidéo, etc., et vous devez trouver qui est la personne ayant commis le crime. Sur le principe vous allez identifier des éléments dans les données, traquer les infos correspondantes ou manquantes, faire le lien entre les éléments, repérer des liens entre personnes ou des transactions, et tout cela avec des requêtes SQL.
Il y a actuellement 4 enquêtes disponibles (et probablement plus à venir). C'est rapide, ludique, joli et ergonomique. L'outil aide en suggérant les mots clés SQL ou les noms de tables par exemple. L'outil dispose d'une zone pour prendre des notes, ce qui est à la fois pratique pour garder trace des requêtes SQL, mais surtout des résultats, et vous en aurez besoin pour les cas compliqués.
Le premier commit du projet date du début du mois, et le projet est donc assez jeune, tout en étant à la fois prometteur, et déjà très sympa.
Note: full disclosure, LinuxFr.org utilise du SQL. Cette information est-elle pertinente ici ? Absolument pas, mais des fois il y a des infos inutiles dans les enquêtes. Et merci à @siltaer d'avoir partagé ce message qui m'a fait découvrir ce jeu.
- lien nᵒ 1 : SQLNoir Solve mysteries through SQL
- lien nᵒ 2 : GitHub SQLNoir
- lien nᵒ 3 : MiXiT 2022 Lætitia Avrot "Meet NULL the UNKNOWN"
- lien nᵒ 4 : DELETEs are difficult
Commentaires : voir le flux Atom ouvrir dans le navigateur
Décès de Jean-Pierre Archambault
Jean-Pierre Archambault est décédé le 23 février 2025. Ancien enseignant et professeur agrégé de mathématiques, il présidait notamment l'association Enseignement Public et Informatique (EPI). Il a été un acteur essentiel des ressources libres et des logiciels pour l'Éducation nationale en France et dans la francophonie.
L'étiquette jean-pierre_archambault vient nous remémorer combien il était actif autour du logiciel libre et de l'éducation depuis longtemps, que nous le croisions régulièrement lors de conférences et d'événements, et combien il était une personne appréciée, active, humaine et de convictions.
LinuxFr.org présente ses plus sincères condoléances à sa famille et à ses proches.
(photo tirée d'une citation pour l'April)
- lien nᵒ 1 : Annonce du décès
- lien nᵒ 2 : Une biographie par l'EPI
- lien nᵒ 3 : Réaction de l'April
- lien nᵒ 4 : Interview pour L'étudiant en 2012
- lien nᵒ 5 : Article Les clés de demain/Le Monde « Il est indispensable que chacun ait une culture informatique »
Commentaires : voir le flux Atom ouvrir dans le navigateur
Revue de presse de l’April pour la semaine 8 de l’année 2025
Cette revue de presse sur Internet fait partie du travail de veille mené par l’April dans le cadre de son action de défense et de promotion du logiciel libre. Les positions exposées dans les articles sont celles de leurs auteurs et ne rejoignent pas forcément celles de l’April.
- [clubic.com] DeepSeek continue de bousculer l'IA en partageant plus largement ses modèles
- [leParisien.fr] Polémique Wikipédia: cinq minutes pour comprendre les critiques qui visent l'encyclopédie en France - Le Parisien
- [Next] Donald Trump supprime l'indépendance des agences de régulation FTC, FCC et SEC
- [Next] GNOME 47.4 et 48 Beta disponibles: quelles nouveautés?
- lien nᵒ 1 : April
- lien nᵒ 2 : Revue de presse de l'April
- lien nᵒ 3 : Revue de presse de la semaine précédente
- lien nᵒ 4 :
Illico Editor : nouveautés depuis 2021
Illico Editor est un (petit) couteau suisse de la qualification de données développé à l’origine pour permettre aux experts métiers de transformer les données sans recourir à la programmation… le tout dans une simple page HTML (pas de serveur Web) donc une utilisation à travers le navigateur.
Aujourd’hui, plus de 150 transformations de données sont disponibles prêtes à l'emploi.
Particularité : chaque transformation exécutée ainsi que son résultat sont inscrits dans un journal de bord créant ainsi une sorte de procédure-type sans effort.
Publié sous licence GPL, le code d’Illico est globalement très basique : standards HTML5/CSS3/JS, et zéro dépendance, bibliothèque ou appel à un code tiers. Les données restent dans le (cache du) navigateur.
Les algorithmes sont très simples. La complexité est plutôt liée à la manière d’imaginer de nouvelles transformations de données, à la fois génériques (paramétrables) tout en restant simples pour l’utilisateur (nombre réduit de paramètres).
- lien nᵒ 1 : Site principal (changement de domaine)
- lien nᵒ 2 : Précédente dépêche (2021)
- Quelques limites à connaître
- Objet de la dépêche
- Nouveaux tutoriels
-
Nouvelles fonctionnalités
- Valeurs en liste : compacter, inverser l’ordre, filtrer
- Valeurs en liste : lister les permutations, mélanger la liste
- enlever les accents et les cédilles de l’en-tête
- Permuter les colonnes
- Numéroter chaque série
- Obtenir les méta-données des colonnes sélectionnées
- Décaler les dates
- Jours de la semaine
- Transformation des périodes « temps : intervalles »
- Calculs
- Convertir d’un système de numération à un autre
- Matrice : transposée, inverser, trier
Dans mon usage, des crashs du navigateur ont été constatés sur des grands jeux de données avec les fonctionnalités qui sollicitent le plus grand nombre de comparaisons (précisément le calcul de la distance d’édition / lignes).
Pour un grand volume de données, mon conseil serait d’opter pour Opera/Vivaldi qui proposent à l’utilisateur d’augmenter la mémoire allouée à la page (plutôt que de faire crasher l’onglet/navigateur) ; de réduire le jeu de données aux colonnes/lignes à traiter (ce qui réduirait la taille), avant de se lancer dans les transformations ; ou d’opter pour des outils plus adaptés à cette volumétrie.
Un test sur des données factices m’avait permis d’identifier des tailles limites de jeu de données : https://illico.ti-nuage.fr/doc/build/html/fct/principes.html#jeu-de-donnees-volumineux
Objet de la dépêcheCette dépêche fait écho à la précédente de janvier 2021.
Au-delà des corrections de bug et des améliorations (gestion des nombres décimaux et négatifs pour les intervalles, options supplémentaires pour décider l’interprétation de “valeurs” vides), je voulais présenter ici la trentaine de nouvelles fonctionnalités/traitements et les nouveaux tutoriels.
Avant de commencerDans Illico, l’expression valeurs en liste désigne
- des données présentées sous la forme a, b, c (le séparateur peut être un caractère ou une chaîne)
- des listes de couples de valeurs xxx:1 / yyy:2 / zzz:3 (un séparateur de liste / + un délimiteur {clé => valeur} ici :
La section tutoriels décrit des cas concrets pour lesquels il n’existe pas de résolution « en 1 étape ».
Dans certains cas, une fonctionnalité a été développée pour couvrir tout ou partie de la résolution.
Ces tutoriels sont détaillés pas à pas dans la section “tutoriels” afin d’être utilisés comme support de formation.
Je résume ici leur logique.
Transposer une matriceAu sens “mathématique” du terme, bascule les lignes en colonnes et vice-versa :
nombre d’étapes/actions du tutoriel : 6
une nouvelle fonctionnalité a été développée par la suite pour transposer les données en 1 clic/étape/action
Comparer (rapidement) des groupes de colonnesComparer des groupes de colonnes prises deux à deux était déjà possible. Cependant, avec un grand nombre de colonne, l’opération pouvait s’avérer fastidieuse et source d’erreurs.
Le tutoriel présente une manière plus générique de comparer un grand nombre de colonne de deux fichiers sources avec le même en-tête, par exemple la description d’une même population sur deux années différentes.
nombre d’étapes/actions du tutoriel : (2 par fichier source) + 4
l’intérêt de ce tutoriel réside surtout dans le fait de rendre la complexité du traitement indépendante du nombre (de paires) de colonnes à comparer
Comparer des lignes dans un fichier cumulOn souhaite identifier des différences mais cette fois au sein d’un même fichier de données décrivant un cumul.
Il peut s’agir par exemple de deux jeux de données mis bout-à-bout décrivant une même population sur deux années différentes.
nombre d’étapes/actions du tutoriel : 3
Créer un fichier cumul à partir de deux sources aux formats prochesLe cas a été rencontré lors d’une analyse de journaux comptables où les jeux de données présentaient des rubriques/codes comptables en colonne.
D’un mois sur l’autre, le nombre et l’ordre de ces colonnes/rubriques différaient. Le tutoriel permet de s’affranchir de ces variations de la structure des données.
nombre d’étapes/actions du tutoriel : (4 par fichier source) + 3
Reconstituer des calendriersAutre cas de figure rencontré, les données décrivent des personnes présentes sur des périodes avec en colonne la date de début, la date de fin, puis les autres données.
À partir de ces données, on recherche les dates/jours exactes qui ont rassemblé le plus de personne.
La résolution consiste à générer l’ensemble des jours (entre la date de début et la date de fin), c’est-à-dire une description des faits à une échelle unitaire/atomique (chaque ligne décrivant alors une date et non une période).
Trois approches sont proposées dans le tutoriel : entre 3 et 6 étapes/actions
Fidélisation (suivre une cohorte)La problématique soulevée était de comprendre les parcours, trajectoires pour une population donnée.
Exemple simplifié : 4 lignes de données décrivent (dans l’ordre chronologique) les états/statuts successifs d’un individu, à raison d’un par ligne : a -> b -> c -> d.
dans la pratique, le jeu de données décrivait une population d’individu avec des trajectoire de 4 à 50 états, parfois circulaires a -> b -> a -> d -> c
On souhaite identifier :
- le parcours par rapport à l’état initial pour l’individu pris en exemple, le résultat sera la relation suivante : a => {b -> c -> d}
- les changements d’état (de proche en proche) pour le même exemple, le résultat sera une liste de couple de valeurs : (a => b), (b => c), (c => d)
- les relations entre l’état initial et n’importe quel autre état du parcours même exemple, le résultat sera trois couples de valeurs : (a => b), (a => c), (a => d)
- les relations entre n’importe quel état du parcours et n’importe quel autre état rencontré par la suite
même exemple, le résultat sera six couples :
- (a => b), (a => c), (a => d)
- (b => c), (b => d)
- (c => d)
La fonctionnalité utilisée possède une option “scénario” avec les 4 choix.
Ainsi, on définit « ce que représente les données » en précisant le ou les séparateurs, et la transformation est appliquée selon la demande.
Les 4 scénarios sont proposés dans le tutoriel : 3 étapes/actions (une 4ème étape est nécessaire si on souhaite étudier à part le 1er état et l’état terminal de la trajectoire)
Nouvelles fonctionnalitésLa majorité des nouvelles fonctionnalités concerne
- des traitements de dates (décalage, conversion)
- des traitements d’intervalles numériques
- des traitements de périodes (intervalles de dates)
Elles sont présentées ci-dessous dans leur rubrique respective (dans l’ordre d’apparition des rubriques dans Illico et dans la documentation).
(dans l’application, chaque écran permettant d’exécuter une transformation possède un lien vers la section/page concernée dans la documentation)
Valeurs en liste : compacter, inverser l’ordre, filtrercompacter les listes
rubrique « valeurs en liste : agrégats"
Pour une liste qui présente des répétitions—a,a,b,c,a,d,b—les deux options de cette transformation permettent d’obtenir :
- a,b,c,a,d,b : réduire à une occurrence, pour chaque série
- a,b,c,d : conserver globalement les premières occurrences
- c,a,d,b : conserver globalement les dernières occurrences
inverser l’ordre des éléments des listes
rubrique « valeurs en liste : structure"
Pour une colonne décrivant des listes d’éléments—a:1, b:2—,
- inverse l’ordre des valeurs des listes (b:2, a:1)
- inverse l’ordre des valeurs des listes imbriquées seulement (1:a, 2:b)
- inverse l’ordre des listes imbriquées et des valeurs dans ces listes (2:b, 1:a)
filtrer ou exclure les valeurs d’une liste
rubrique « valeurs en liste : filtres"
compare les listes de valeurs d’une colonne par rapport à une autre colonne de référence
- égal
- différent de
- supérieur/inférieur ou égal à
- strictement supérieur/inférieur à
réduire la liste à certaines clés
conserver/exclure certains couples {clé:valeur} lorsque la clé existe dans une autre colonne (qui contient pour chaque ligne la liste de clés à conserver ou à exclure)
Par exemple—et sans devoir utiliser des regex/expressions rationnelles—la liste 2021=3,2022=1,2024=4 pourra être réduite à 2022=1,2024=4 si la clé 2021 existe dans la colonne de contrôle.
Valeurs en liste : lister les permutations, mélanger la listerubrique valeurs en liste : enrichissement
lister les permutations des valeurs d’une liste
produit la liste de toutes les permutations des valeurs des listes de la colonne sélectionnée.
mélanger les valeurs de la liste
applique le mélange de Fisher-Yates sur les valeurs de la liste
enlever les accents et les cédilles de l’en-têterubrique « en-tête"
surtout utile lorsque l’on part d’un tableur et que l’on cherche à injecter les données dans une base de données ne tolérant pas ces caractères dans les en-têtes
Permuter les colonnesrubrique « colonnes : ordre"
Dans le cas d’un export de données depuis un logiciel métier, ou suite à certaines transformations, certaines colonnes peuvent être générées dans un ordre qui ne s’avère pas très intuitif.
Cette nouvelle fonctionnalité inverse en 1 clic l’ordre des colonnes sélectionnées en permutant (au choix)
- 1ʳᵉ et 2ᵉ, 3ᵉ et 4ᵉ, etc.
- 1ʳᵉ et dernière, 2ᵉ et avant-dernière, etc.
rubrique “lignes”
Dans Illico, le terme série désigne une suite de lignes contiguës qui possèdent la même valeur dans la colonne sélectionnée (un identifiant par exemple).
Si l’identifiant réapparaît plus loin dans les données, il s’agira d’une nouvelle série.
(une autre transformation permet déjà de numéroter chaque ligne de la série)
Obtenir les méta-données des colonnes sélectionnéesrubrique “agrégats”
Pour les colonnes sélectionnées, indique
- si la colonne ne contient que des valeurs uniques (les valeurs vides sont comptées à part)
- le nombre de lignes sans valeur (valeur vide)
- le nombre de valeurs renseignées (valeur non-vide)
- la cardinalité : nombre de valeurs différentes rencontrées dans la colonne
rubrique “temps”
décaler les dates avec 1 constante (saisie par l’utilisateur)
permet de décaler les dates d’une colonne à partir d’une constante (on précise l’unité : nombre de jours, de semaines, de mois ou d’années)
décaler des dates selon 1 autre colonne
idem précédemment mais en se basant sur les valeurs d’une autre colonne plutôt qu’une constante
Jours de la semainerubrique “temps”
donner le nom des jours de la semaine
la date est alors recodée : lundi, mardi…
compter chacun des jours de la semaine
nombre de lundis, de mardis, etc. dans l’intervalle décrit par des colonnes début et fin de la période
obtenir le numéro du jour dans l’année
1 pour le 1ᵉʳ janvier, 32 pour le 1ᵉʳ février…
Transformation des périodes « temps : intervalles »compléter un intervalle de date (2 colonnes : début et fin de la période)
crée une liste de jour/date dans l’intervalle décrit
rechercher une date dans un intervalle de date
compare 1 colonne (date recherchée) par rapport à 2 autres colonnes décrivant une période (début et fin de la période)
combiner deux périodes (4 colonnes)
option (au choix) : obtenir
- une fusion : période englobant les deux [min, max]
- une union : période englobant les deux seulement si intersection
- une intersection : plus petite période commune
comparer les dates et une liste de seuils (saisie par l’utilisateur)
détecter des collisions de périodes
portée de la détection
- rechercher pour l’ensemble des données
- rechercher dans les lignes qui partagent un même identifiant (les lignes comparées ne sont pas forcément contiguës)
- rechercher dans les lignes qui décrivent une série (lignes contiguës avec un même identifiant)
rubrique “calculs”
calculer une opération sur 1 colonne : options
options :
- opérations : minimum, maximum, moyenne, somme
- valeurs vides : ignorées ou traduites par zéro
- calcul : total ou cumulé
- option si cumulé : en partant de la première ou dernière ligne
- résultat : global ou local
- option si local : pour chaque série ou pour chaque identifiant
calculer une opération avec 1 constante (saisie par l’utilisateur)
calculer une somme ou une moyenne sur x colonnes
Convertir d’un système de numération à un autrerubrique “enrichissement”
conversion depuis et vers une base binaire, octale, décimale, hexadécimale
Matrice : transposée, inverser, trierrubrique “matrice”
calculer la transposée
Transpose le jeu de données : les lignes deviennent les colonnes et inversement ; la ligne d’en-tête devient la première colonne ; la première colonne devient la ligne d’en-tête.
inverser l’ordre des lignes
Inverse l’ordre des lignes du jeu de données : la première ligne devient la dernière, la dernière devient la première, etc.
trier par ordre alphabétique
options
- ordre des lettres : A…Z…a…z…É…é ou A…É…Z…a…é…z
- placer les valeurs vides : au début ou à la fin
trier par ordre numérique
option : les valeurs vides sont
- les plus petites (seront placées au début du tableau)
- les plus grandes (seront placées à la fin du tableau)
- égales à zéro
trier par ordre chronologique
option : les valeurs vides sont
- dans le passé lointain
- dans un futur lointain
- égales à la date du jour
- égales à une date précise (à saisir)
Commentaires : voir le flux Atom ouvrir dans le navigateur
Programmer des démonstrations : une modeste invitation aux assistants de preuve
En principe, une démonstration mathématique ne fait que suivre des règles logiques bien définies, et devrait donc pouvoir être encodée informatiquement et vérifiée par un ordinateur. Où en est-on dans la pratique et dans la théorie ? Petit tour au pays des assistants de preuve, des langages de programmation dédiés aux démonstrations, et de leur fondement théorique le plus commun, la théorie des types.
- lien nᵒ 1 : Why formalize mathematics? par Patrick Massot
- Vérifier des programmes
- Vérifier des démonstrations mathématiques
- Brouwer-Heyting-Kolmogorov
- Curry-Howard
- Quantificateurs et types dépendants
- Logique intuitionniste
- Quelques exemples
- Quelques succès de la formalisation
- La recherche en théorie des types
- Conclusion
Comme nous sommes sur LinuxFr.org, je devrais peut-être commencer par ceci : nous passons énormément de temps à découvrir des bugs, et pour les personnes du développement logiciel, à les comprendre, à les résoudre, et de préférence à les éviter en écrivant des tests.
Dans une formation universitaire de base en informatique, on rencontre des algorithmes, mais aussi des méthodes pour prouver que ces algorithmes terminent et répondent bien au problème posé. Les premières introduites sont typiquement les variants de boucle (montrer qu’une certaine valeur décroît à chaque itération, ce qui assure que le programme termine si elle ne peut pas décroître à l’infini), et les invariants de boucle (montrer qu’une certaine propriété vraie au début d’une boucle est préservée entre deux itérations, ce qui assure qu’elle reste encore vraie à la fin de la boucle).
On a donc, d’une part, un algorithme, implémentable sur machine, d’autre part une preuve, sur papier, que l’algorithme est correct. Mais si l’implémentation a une erreur par rapport à l’algorithme sur papier ? Et puisque nous n’arrêtons pas de nous tromper dans nos programmes, il est fort possible que nous nous trompions dans notre preuve (qui n’a jamais oublié qu’il fallait faire quelque chose de spécial dans le cas ?).
En tant que programmeurs, on peut imaginer une approche où non seulement l’algorithme est implémenté, mais sa preuve de terminaison et de correction est aussi « implémentée », c’est-à-dire encodée dans un langage qui ressemble à un langage de programmation, pour être ensuite non pas interprétée ou compilée mais vérifiée.
La vérification est un très vaste domaine de l’informatique, dont je ne suis pas spécialiste du tout, et dans lequel il existe énormément d’approches : la logique de Hoare (voir par exemple l’outil why3), qui est essentiellement un raffinement des variants et invariants de boucle, la logique de séparation spécialement conçue pour raisonner sur la mémoire mutable (voir Iris), le model checking qui se concentre sur des programmes d’une forme particulièrement simple (typiquement des systèmes de transition finis) pour en vérifier des propriétés de façon complètement automatisée, etc.
Dans cette dépêche, je vais parler d’une approche avec quelques caractéristiques particulières :
On vérifie des programmes purement fonctionnels (pas d’effets de bord, même si on peut les simuler).
Le même langage mélange à la fois les programmes et leurs preuves.
Plus précisément, le langage ne fait pas (ou peu) de distinction entre les programmes et les preuves.
Pour se convaincre de l’ampleur que les démonstrations ont prise dans les mathématiques contemporaines, il suffit d’aller jeter un œil, par exemple, au projet Stacks : un livre de référence sur la géométrie algébrique, écrit collaborativement sur les 20 dernières années, dont l’intégrale totalise plus de 7500 pages très techniques. Ou bien la démonstration du théorème de classification des groupes finis simples : la combinaison de résultats répartis dans les dizaines de milliers de pages de centaines d’articles, et une preuve « simplifiée » toujours en train d’être écrite et qui devrait faire plus de 5000 pages. Ou bien le théorème de Robertson-Seymour, monument de la théorie des graphes aux nombreuses applications algorithmiques : 20 articles publiés sur 20 ans, 400 pages en tout. Ou bien, tout simplement, le nombre de références dans la bibliographie de la moindre thèse ou d’articles publiés récemment sur arXiv.
Inévitablement, beaucoup de ces démonstrations contiennent des erreurs. Parfois découvertes, parfois beaucoup plus tard. Un exemple assez célèbre est celui d’un théorème, qui aurait été très important s’il avait été vrai, publié en 1989 par Vladimir Voedvodsky, un célèbre mathématicien dont je vais être amené à reparler plus bas, avec Mikhail Kapranov. Comme raconté par Voedvodsky lui-même, un contre-exemple a été proposé par Carlos Simpson en 1998, mais jusqu’en 2013, Voedvodsky lui-même n’était pas sûr duquel était faux entre sa preuve et le contre-exemple !
Il y a aussi, souvent, des « trous », qui ne mettent pas tant en danger la démonstration mais restent gênants : par exemple, « il est clair que la méthode classique de compactification des espaces Lindelöf s’applique aussi aux espaces quasi-Lindelöf », quand l’auteur pense évident qu’un argument existant s’adapte au cas dont il a besoin mais que ce serait trop de travail de le rédiger entièrement. Donc, assez naturellement, un but possible de la formalisation des maths est de produire des démonstrations qui soient certifiées sans erreur (et sans trou).
Mais c’est loin d’être le seul argument. On peut espérer d’autres avantages, qui pour l’instant restent de la science-fiction, mais après tout ce n’est que le début : par exemple, on peut imaginer que des collaborations à grande échelle entre beaucoup de mathématiciens deviennent possibles, grâce au fait qu’il est beaucoup plus facile de réutiliser le travail partiel de quelqu’un d’autre s’il est formalisé que s’il est donné sous formes d’ébauches informelles pas complètement rédigées.
Brouwer-Heyting-KolmogorovParmi les assistants de preuve existants, la plupart (mais pas tous) se fondent sur une famille de systèmes logiques rangés dans la famille des « théories des types ». L’une des raisons pour lesquelles ces systèmes sont assez naturels pour être utilisés en pratique est qu’en théorie des types, les preuves et les programmes deviennent entièrement confondus ou presque, ce qui rend facile le mélange entre les deux.
Mais comment est-ce qu’un programme devient une preuve, au juste ? L’idée de base est appelée interprétation de Brouwer-Heyting-Kolomogorov et veut que les preuves mathématiques se comprennent de la façon suivante :
Le moyen de base pour prouver une proposition de la forme « et » est de fournir d’une part une preuve de et une preuve de . En d’autres mots, une preuve de « et » rassemble en un même objet une preuve de et une preuve de . Mais en termes informatiques, ceci signifie qu’une preuve de « et » est une paire d’une preuve de et d’une preuve de .
De même, pour prouver « ou », on peut prouver , ou on peut prouver . Informatiquement, une preuve de « ou » va être une union disjointe : une preuve de ou une preuve de , avec un bit pour savoir dans quel cas on est.
Pour prouver « Vrai », il suffit de dire « c’est vrai » : on a une unique preuve de « Vrai ».
On ne doit pas pouvoir prouver « Faux », donc une preuve de « Faux » n’existe pas.
Et le plus intéressant : pour prouver « si alors », on suppose temporairement et on en déduit . Informatiquement, ceci doit devenir une fonction qui prend une preuve de et renvoie une preuve de .
L’interprétation de Brouwer-Heyting-Kolmogorov est informelle, et il existe plusieurs manières de la rendre formelle. Par exemple, on peut interpréter tout ceci par des programmes dans un langage complètement non-typé, ce qui s’appelle la réalisabilité.
Mais en théorie des types, on prend plutôt un langage statiquement typé pour suivre l’idée suivante : si une preuve de et est une paire d’une preuve de et d’une preuve de , alors le type des paires de et peut se comprendre comme le type des preuves de « et ». On peut faire de même avec les autres types de preuves, et ceci s’appelle la correspondance de Curry-Howard. Autrement dit, là où Brouwer-Heyting-Kolmogorov est une correspondance entre les preuves et les programmes, Curry-Howard est un raffinement qui met aussi en correspondance les propositions logiques avec les types du langage, et la vérification des preuves se confond entièrement avec le type checking.
Sur les cas que j’ai donnés, la correspondance de Curry-Howard donne :
La proposition « et » est le type des paires d’un élément de et d’un élément de ,
La proposition « ou » est le type somme de et (comme Either en Haskell et OCaml, les tagged unions en C, et std::variant en C++ : l’un ou l’autre, avec un booléen pour savoir lequel),
La proposition « Vrai » est le type trivial à une seule valeur (comme () en Haskell et Rust, unit en OCaml),
La proposition « Faux » est le type vide qui n’a aucune valeur (comme ! en Rust),
La proposition « si alors » est le type des fonctions qui prennent un argument de type et renvoient une valeur de type .
La version de Curry-Howard que j’ai esquissée donne une logique dite « propositionnelle » : il n’y a que des propositions, avec des connecteurs entre elles. Mais en maths, on ne parle évidemment pas que des propositions. On parle de nombres, de structures algébriques, d’espaces topologiques, …, bref, d’objets mathématiques, et des propriétés de ces objets. Les deux types principaux de propositions qui manquent sont ce qu’on appelle les quantificateurs : « Pour tout , … » et « Il existe tel que… ». Ici, ce qui est une évidence en logique devient moins évident, mais très intéressant, du côté des programmes.
Prenons pour l’exemple le théorème des deux carrés de Fermat, qui énonce (dans l’une de ses variantes) qu’un nombre premier impair est de la forme si et seulement s’il peut s’écrire comme somme de deux carrés parfaits. À quoi doit ressembler le type associé à cette proposition ? Par analogie avec les implications, on a envie de dire que cela devrait être une fonction, qui prend un nombre premier impair , et renvoie une preuve de l’équivalence. Problème : ce qui est à droite de l’équivalence est une proposition paramétrée par . Autrement dit, en notant le type des nombres premiers impairs, on ne veut plus un simple type fonction , mais un type fonction où le type de retour peut dépendre de la valeur passée à la fonction, noté par exemple . Ces types qui dépendent de valeurs sont appelés types dépendants.
Dans les langages de programmation populaires, il est rare de trouver des types dépendants. Mais on en retrouve une forme faible en C avec les tableaux de longueur variable (VLA pour « variable-length arrays ») : on peut écrire
… f(int n) { int array[n]; … }qui déclare un tableau dont la taille n est une expression. Néanmoins, en C, même si on dispose de ce type tableau qui est en quelque sorte dépendant, on ne peut pas écrire une fonction « int[n] f(int n) » qui renvoie un tableau dont la longueur est passée en paramètre. Plus récemment, en Rust, il existe les const generics, où des valeurs se retrouvent dans les types et où on peut écrire fn f<const n: usize>() -> [u8; n], ce qui est un vrai type dépendant, mais cette fois avec la restriction assez sévère que toutes ces valeurs peuvent être calculées entièrement à la compilation, ce qui à cause de la façon dont fonctionne ce type de calcul en Rust empêche par exemple les allocations mémoire. (Donc l’implémentation est assez différente, elle efface ces valeurs en « monomorphisant » tous les endroits où elles apparaissent.)
En théorie des types, le langage est (normalement) purement fonctionnel, donc les problèmes d’effets de bord dans les valeurs à l’intérieur des types dépendants ne se pose pas. Le type checking peut déclencher des calculs arbitrairement complexes pour calculer les valeurs qui se trouvent dans les types.
Et le « il existe », au fait, à quoi correspond-il ? Cette fois, ce n’est plus une fonction dépendante mais une paire dépendante : une preuve de « Il existe tel que » est une paire d’une valeur et d’une preuve de . La différence avec une paire normale est que le type du deuxième élément peut dépendre de la valeur du premier élément.
Comme on peut commencer à s’en douter, le fait d’avoir des types dépendants est utile pour prouver des affirmations mathématiques, mais aussi, bien qu’il puisse sembler inhabituel, pour prouver des programmes, et plus précisément pour encoder des propriétés des valeurs dans les types. Là où on aurait dans un langage moins expressif une fonction qui renvoie deux listes, avec une remarque dans la documentation qu’elles sont toujours de même taille, dans un langage avec des types dépendants, on peut renvoyer un triplet d’un entier , d’une liste dont le type indique qu’elle est de taille , et une deuxième liste elle aussi de taille . Et là où on aurait un deuxieme_liste[indice_venant_de_la_premiere] avec un commentaire que cela ne peut pas produire d’erreur, car les deux listes sont de même taille, on a un programme qui utilise la garantie que les deux listes sont de même taille, et le typage garantit statiquement que cette opération t[i] ne produira pas d’erreur.
Logique intuitionnisteReprenons l’exemple du théorème des deux carrés de Fermat. Nous pouvons maintenant traduire cette proposition en un type : celui des fonctions qui prennent un nombre premier impair et renvoient une paire de :
Une fonction qui prend tel que et renvoie deux entiers accompagnés d’une preuve que ,
Réciproquement, une fonction qui prend et une preuve de , et renvoie tel que .
Prouver le théorème des deux carrés de Fermat en théorie des types, c’est donner un élément (on dit plutôt « habitant ») de ce type, soit un programme dont le langage peut vérifier qu’il a ce type. Mais que fait au juste ce programme quand on l’exécute ? On voit qu’il permet notamment de calculer une décomposition d’un nombre premier impair congru à 1 modulo 4 comme somme de deux carrés.
Là, c’est le côté « programmes » qui apporte un élément moins habituel du côté « preuves » : l’exécution d’un programme va correspondre à un processus de simplification des preuves. Notamment, si on a une preuve de « si alors » et une preuve de , on peut prendre la preuve de et remplacer chaque utilisation de l’hypothèse dans la preuve de « si alors », pour obtenir une preuve de qui peut contenir de multiples copies d’une même preuve de . Cette opération de simplification du côté logique correspond naturellement au fait que la manière en théorie des types de prouver à partir d’une preuve de et d’une preuve de est tout simplement d’écrire , et que calculer , informatiquement, se fait bien en remplaçant le paramètre de à tous les endroits où il apparaît par la valeur et à simplifier le résultat. On dit que la logique de Curry-Howard est constructive, parce qu’elle se prête à une interprétation algorithmique.
Mais ceci peut sembler gênant. Par exemple, il est trivial en maths « normales » de prouver que tout programme termine ou ne termine pas. Mais par Curry-Howard, une preuve que tout programme termine ou ne termine pas doit être une fonction qui prend un programme, et qui renvoie soit une preuve qu’il termine, soit une preuve qu’il ne termine pas. Autrement dit, si cette proposition censément triviale était prouvable dans Curry-Howard, on aurait un algorithme pour résoudre le problème de l’arrêt, ce qui est bien connu pour être impossible.
L’explication à cette différence tient au fait que la preuve « triviale » de cette proposition utilise une règle de déduction qui a un statut un peu à part en logique, dite règle du tiers exclu : pour n’importe quelle proposition , sans aucune hypothèse, on peut déduire « ou (non ) » (autrement dit, que est vraie ou fausse). Or cette règle n’admet pas d’interprétation évidente par Curry-Howard : le tiers exclu devrait prendre une proposition et renvoyer soit une preuve de , soit une preuve que est fausse (ce qui s’encode par « si alors Faux »), autrement dit, le tiers exclu devrait être un oracle omniscient capable de vous dire si une proposition arbitraire est vraie ou fausse, et ceci est bien évidemment impossible.
(Cela dit, si vous voulez vous faire mal à la tête, apprenez que c’est l’opérateur call/cc et pourquoi l’ajouter permet de prouver le tiers exclu. Exercice : call/cc existe dans de vrais langages, comme Scheme, pourtant on vient de voir que le tiers exclu semble nécessiter un oracle omniscient, comment expliquer cela ?)
Pour être précis, la logique sans le tiers exclu est dite intuitionniste (le terme constructive étant un peu flou, alors que celui-ci est précis). On peut faire des maths en restant entièrement en logique intuitionniste, et même si ce n’est pas le cas de l’écrasante majorité des maths, il existe tout de même un certain nombre de chercheurs qui le font, et ceci peut avoir divers intérêts. Il y a notamment l’interprétation algorithmique des théorèmes, mais aussi, de manière beaucoup plus avancée, le fait que certaines structures mathématiques (topos, ∞-topos et consorts) peuvent s’interpréter comme des sortes d’univers mathématiques alternatifs régis par les règles de la logique intuitionniste (techniquement, des « modèles » de cette logique), et que parfois il est plus simple de prouver un théorème en le traduisant à l’intérieur de l’univers et en prouvant cette version traduite de manière intuitionniste.
Pour pouvoir malgré tout raisonner en théorie des types de manière classique (par opposition à intuitionniste), il suffit de postuler le tiers exclu comme axiome. Du point de vue des programmes, cela revient à rajouter une constante qui est supposée avoir un certain type mais qui n’a pas de définition (cela peut donc rendre les programmes impossibles à exécuter, ce qui est normal pour le tiers exclu).
Quelques exemplesSi vous aviez décroché, c’est le moment de reprendre. Parlons un peu des assistants de preuve qui existent. Les plus connus sont :
Rocq, anciennement nommé Coq, développé à l’Inria depuis 1989, écrit en OCaml, sous licence LGPL 2.1. Il est assez lié à l’histoire de la théorie des types, car il a été créé par Thierry Coquand comme première implémentation du calcul des constructions, une théorie des types inventée par Coquand et devenue l’une des principales existantes. (Oui, Coq a été renommé en Rocq à cause de l’homophonie en anglais entre « Coq » et « cock ». J’apprécierais que les commentaires ne se transforment pas en flame war sur ce sujet très peu intéressant, merci.)
Lean, créé par Leonardo de Moura et développé depuis 2013 chez Microsoft Research, écrit en C++, placé sous licence Apache 2.0.
Agda, créé par Ulf Norrell en 1999, écrit en Haskell et sous licence BSD 1-clause.
D’autres que je connais moins, notamment Isabelle et F* (liste sur Wikipédia).
Pour illustrer comment peuvent fonctionner les choses en pratique, voici un exemple très simple de code en Agda :
open import Agda.Primitive using (Level) open import Data.Product using (_×_; _,_) swap : {ℓ₁ ℓ₂ : Level} → {P : Set ℓ₁} {Q : Set ℓ₂} → P × Q → Q × P swap (p , q) = (q , p)Vue comme un programme, cette fonction swap inverse simplement les deux éléments d’une paire. Vue comme une preuve, elle montre que pour toutes propositions et , si et , alors et . Comme le veut Curry-Howard, les deux ne sont pas distingués. Les types et sont eux-mêmes dans des types avec un « niveau » , ceci parce que, pour des raisons logiques, il serait incohérent que le type des types soit de son propre type, donc on a un premier type de types , qui est lui-même de type , et ainsi de suite avec une hiérarchie infinie de niveaux appelés univers. À un niveau plus superficiel, on remarquera qu’Agda a une syntaxe qui ressemble fort à Haskell (et utilise intensivement Unicode).
Voilà la même chose en Rocq :
Definition swap {P Q : Prop} : P /\ Q -> Q /\ P := fun H => match H with conj p q => conj q p end.La syntaxe est assez différente et ressemble plutôt à OCaml (normal, vu que Rocq est écrit en OCaml et Agda en Haskell). Mais à un niveau plus profond, on voit apparaître un type Prop dont le nom évoque furieusement les propositions. Or j’avais promis que les propositions seraient confondues avec les types, donc pourquoi a-t-on un type spécial pour les propositions ?
En réalité, pour diverses raisons, il peut être intéressant de briser l’analogie d’origine de Curry-Howard et de séparer les propositions et les autres types en deux mondes qui se comportent de façon extrêmement similaire mais restent néanmoins distincts. Notamment, un principe qu’on applique sans réfléchir en maths est que si deux propositions sont équivalentes, alors elles sont égales (extensionnalité propositionnelle), mais on ne veut clairement pas ceci pour tous les types (on peut donner des fonctions bool -> int et int -> bool, pourtant on ne veut certainement pas bool = int), donc séparer les propositions des autres permet d’ajouter l’extensionnalité propositionnelle comme axiome. (Mais il y a aussi des différences comme l'imprédicativité dans lesquelles je ne vais pas rentrer.)
Et voici encore le même code, cette fois en Lean :
def swap {P Q : Prop} : P ∧ Q → Q ∧ P := fun ⟨p, q⟩ => ⟨q, p⟩À part les différences de syntaxe, c’est très similaire à Rocq, parce que Lean a aussi une séparation entre les propositions et les autres types.
Cependant, en Rocq et Lean, on peut aussi prouver la même proposition de façon différente :
Lemma swap {P Q : Prop} : P /\ Q -> Q /\ P. Proof. intros H. destruct H as [p q]. split. - apply q. - apply p. Qed.et
def swap {P Q : Prop} : P ∧ Q → Q ∧ P := by intro h have p := h.left have q := h.right exact ⟨q, p⟩Avec Proof. ou by, on entre dans un mode où les preuves ne sont plus écrites à la main comme programmes, mais avec des tactiques, qui génèrent des programmes. Il existe toutes sortes de tactiques, pour appliquer des théorèmes existants, raisonner par récurrence, résoudre des inégalités, ou même effectuer de la recherche automatique de démonstration, ce qui s’avère extrêmement utile pour simplifier les preuves.
Ce mode « tactiques » permet aussi d’écrire la preuve de façon incrémentale, en faisant un point d’étape après chaque tactique pour voir ce qui est prouvé et ce qui reste à prouver. Voici par exemple ce qu’affiche Rocq après le destruct et avant le split :
P, Q : Prop p : P q : Q ============================ Q /\ PCette notation signifie que le contexte ambiant contient les variables P et Q de type Prop ainsi que p une preuve de P (donc un élément du type P) et q une preuve de Q. Le Q /\ P en dessous de la barre horizontale est le but à prouver, c’est-à-dire le type dont on cherche à construire un élément.
Agda fonctionne assez différemment : il n’y a pas de tactiques, mais il existe néanmoins un système de méta-programmation qui sert à faire de la recherche de preuves (donc contrairement à Rocq et Lean, on n’écrit pas la majeure partie des preuves avec des tactiques, mais on peut se servir d’un équivalent quand c’est utile). Pour écrire les preuves incrémentalement, on met ? dans le programme quand on veut ouvrir une sous-preuve, et Agda va faire le type-checking de tout le reste et donner le contexte à l’endroit du ?.
Quelques succès de la formalisationEn 2025, la formalisation reste très fastidieuse, mais elle a déjà eu plusieurs grands succès :
- Le théorème des quatre couleurs, formalisé en Rocq (2005).
- Le théorème de Feit-Thompson (étape dans la fameuse classification des groupes finis simples) en Rocq (2012).
- Un théorème de Peter Scholze sur les « espaces vectoriels liquides » en Lean (2022).
- Le retournement de la sphère en Lean (2022).
- La valeur de BB(5) en Rocq (2024).
Actuellement, Lean a réussi à attirer une communauté de mathématiciens qui développent mathlib (1,1 million de lignes de code Lean au moment où j’écris), une bibliothèque de définitions et théorèmes mathématiques qui vise à être la plus unifiée possible.
Les équivalents dans d’autres assistants de preuve se développent même s’ils ne sont pas (encore) aussi gros : citons mathcomp, unimath, agda-unimath entre autres.
Un autre grand succès, dans le domaine de la vérification cette fois, est CompCert (malheureusement non-libre), qui est un compilateur C entièrement écrit en Rocq et vérifié par rapport à une spécification du C également encodée en Rocq.
La recherche en théorie des typesLa théorie des types est un domaine de recherche à part entière, qui vise à étudier du point de vue logique les théories des types existantes, et à en développer de nouvelles pour des raisons à la fois théoriques et pratiques.
Historiquement, une grande question de la théorie des types est celle de comprendre à quel type doivent correspondre les propositions d’égalité. Par exemple, on veut que deux propositions équivalentes soient égales, et que deux fonctions qui prennent les mêmes valeurs soient égales, et éventuellement pour diverses raisons que deux preuves de la même proposition soient égales, mais s’il est facile d’ajouter toutes ces choses comme axiomes, il est très compliqué de les rendre prouvables sans obtenir, comme avec le tiers exclu, des programmes qui ne peuvent pas s’exécuter à cause des axiomes qui sont déclarés sans définition.
Vladimir Voedvodsky a fait une contribution majeure en proposant un nouvel axiome, appelé univalence, qui dit très sommairement que si deux types ont la même structure (on peut donner une « équivalence » entre les deux), alors ils sont en fait égaux (résumé simpliste à ne pas prendre au mot). Cet axiome est très pratique pour faire des maths parce qu’on travaille souvent avec des objets qui ont la même structure (on dit qu’ils sont isomorphes), et qui doivent donc avoir les mêmes propriétés, et cet axiome permet de les identifier (même s’il a aussi des conséquences qui peuvent paraître choquantes). Sa proposition a donné naissance à une branche appelée théorie homotopique des types, qui explore les maths avec univalence. Le prix à payer est que les types ne se comprennent plus comme de simples ensembles de valeurs (ou de preuves d’une proposition), mais comme des espaces géométriques munis de toute une structure complexe (techniquement, les égalités sont des chemins entre points, et il y a des égalités non-triviales, des égalités entre égalités, etc.), et la compréhension de ces espaces-types est fondée sur la théorie de l’homotopie. Il y a bien d’autres théories des types, avec univalence ou non : théorie cubique des types, théorie des types observationnelle, etc.
ConclusionJ’espère avoir communiqué un peu de mon enthousiasme pour le domaine (dans lequel je suis probablement parti pour démarrer une thèse). Si vous voulez apprendre un assistant de preuve, une ressource assez abordable est la série Software Foundations avec Rocq. Il existe également Theorem proving in Lean 4 et divers tutoriels Agda. Vous pouvez aussi essayer ces assistants de preuve directement dans votre navigateur : Rocq, Lean ou Agda. Et bien sûr les installer et jouer avec : Rocq, Lean, Agda.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Agenda du Libre pour la semaine 9 de l’année 2025
Calendrier Web, regroupant des événements liés au Libre (logiciel, salon, atelier, install party, conférence), annoncés par leurs organisateurs. Voici un récapitulatif de la semaine à venir. Le détail de chacun de ces 37 événements (France: 34, internet: 3) est en seconde partie de dépêche.
- lien nᵒ 1 : April
- lien nᵒ 2 : Agenda du Libre
- lien nᵒ 3 : Carte des événements
- lien nᵒ 4 : Proposer un événement
- lien nᵒ 5 : Annuaire des organisations
- lien nᵒ 6 : Agenda de la semaine précédente
- lien nᵒ 7 : Agenda du Libre Québec
-
- [FR Montpellier] Émission | Radio FM-Plus | Temps Libre | Diffusion – Le lundi 24 février 2025 de 09h00 à 10h00.
- [internet] Mapathon 2024-2025 par CartONG – Le lundi 24 février 2025 de 18h00 à 20h00.
- [FR Saint-Étienne] OpenStreetMap, rencontre Saint-Étienne et sud Loire – Le lundi 24 février 2025 de 19h00 à 21h00.
- [internet] Émission «Libre à vous!» – Le mardi 25 février 2025 de 15h30 à 17h00.
- [FR Vallauris – Sophia Antipolis] Rencontre Accès Libre – Le mardi 25 février 2025 de 18h00 à 21h00.
- [FR Pau] Assemblée générale de l’association PauLLA – Le mardi 25 février 2025 de 19h00 à 22h00.
- [FR Lille] Permanence associative autour du Libre – Le mardi 25 février 2025 de 20h00 à 22h00.
- [internet] Permanence numérique (visio) – Le mardi 25 février 2025 de 20h00 à 21h30.
- [FR Le Mans] Permanence du mercredi – Le mercredi 26 février 2025 de 12h30 à 17h00.
- [FR Le Blanc] Ateliers “Libres” – Le mercredi 26 février 2025 de 14h00 à 14h00.
- [FR Le Blanc] Ateliers “Libres” de Linux au Blanc – Le mercredi 26 février 2025 de 14h00 à 17h00.
- [FR Pessac] Cours gratuit d’Espéranto, langue Libre – Le mercredi 26 février 2025 de 17h30 à 19h00.
- [FR Vandœuvre-lès-Nancy] Réunion OpenStreetMap – Le mercredi 26 février 2025 de 18h00 à 20h00.
- [FR Beauvais] Sensibilisation et partage autour du Libre – Le mercredi 26 février 2025 de 18h00 à 20h00.
- [FR Simandre] Causerie numérique – Le mercredi 26 février 2025 de 18h00 à 20h00.
- [FR Parempuyre] Participez au prochain ĞBlabla – Le mercredi 26 février 2025 de 18h30 à 22h30.
- [FR Saint Laurent du Pont] Permanence Rézine Chartreuse – Le mercredi 26 février 2025 de 19h00 à 20h00.
- [FR Montpellier] Permanence | OpenStreetMap | HérOSM (hybride) – Le mercredi 26 février 2025 de 19h00 à 22h00.
- [FR Joué-lès-Tours] Atelier du Libre – Le jeudi 27 février 2025 de 13h30 à 16h00.
- [FR Sète] Permanence | GNU/Linux et Logiciels Libres – Le jeudi 27 février 2025 de 18h00 à 20h00.
- [FR Toulouse] Repas du Libre – Le jeudi 27 février 2025 de 20h30 à 23h00.
- [FR Quimperlé] Point info GNU/Linux – Le vendredi 28 février 2025 de 13h30 à 17h30.
- [FR Lyon] Permanence contre l’obsolescence – Le vendredi 28 février 2025 de 16h00 à 18h30.
- [FR Toulon] Install Partie Linux – Le vendredi 28 février 2025 de 17h00 à 21h00.
- [FR Annecy] Réunion hebdomadaire AGU3L Logiciels Libres – Le vendredi 28 février 2025 de 20h00 à 23h59.
- [FR Marignier] Utilisation d’internet – Le samedi 1 mars 2025 de 09h00 à 12h00.
- [FR Contamine sur Arve] Bidouille Informatique – Le samedi 1 mars 2025 de 09h00 à 12h00.
- [FR Vanves] Portes ouvertes – Installations – Dépannages – Le samedi 1 mars 2025 de 09h30 à 18h00.
- [FR Figeac] Café bidouille, réparation informatique – Le samedi 1 mars 2025 de 10h00 à 13h00.
- [FR Ivry sur Seine] Cours de l’École du Logiciel Libre – Le samedi 1 mars 2025 de 10h30 à 18h30.
- [FR Rennes] Atelier Pixel Quest – Le samedi 1 mars 2025 de 14h00 à 17h00.
- [FR Rennes] Atelier Pixel Quest – Le samedi 1 mars 2025 de 14h00 à 17h00.
- [FR Le Mans] Permanence mensuelle du samedi – Le samedi 1 mars 2025 de 14h00 à 18h00.
- [FR Quimper] Permanence Linux Quimper – Le samedi 1 mars 2025 de 16h00 à 18h00.
- [FR Vire] Atelier Cartographie participative – Le samedi 1 mars 2025 de 17h00 à 19h00.
- [FR Montigny Le Bretonneux] Soirée Cult' : Plongée dans l’univers du hacking – Le samedi 1 mars 2025 de 19h00 à 20h30.
- [FR Gaillac] Repair café – Le dimanche 2 mars 2025 de 10h00 à 13h00.
Montpel'libre réalise une série d’émissions régulières à la Radio FM-Plus intitulées « Temps Libre ». Ces émissions sont la présentation hebdomadaire des activités de Montpel’libre.
Après le jingle où l’on présente brièvement Montpel'libre, nous donnerons un coup de projecteur sur les activités qui seront proposées prochainement.
Ces émissions seront l’occasion pour les auditeurs de découvrir plus en détails les logiciels libres et de se tenir informés des dernières actualités sur le sujet.
Alors, que vous soyez débutant ou expert en informatique, que vous ayez des connaissances avancées du logiciel libre ou que vous souhaitiez simplement en savoir plus, Montpel'libre, au travers de cette émission, se fera un plaisir pour répondre à vos attentes et vous accompagner dans votre découverte des logiciels libres, de la culture libre et des communs numériques.
Vous vous demandez peut-être ce qu’est un logiciel libre. Il s’agit simplement d’un logiciel dont l’utilisation, la modification et la diffusion sont autorisées par une licence qui garantit les libertés fondamentales des utilisateurs. Ces libertés incluent la possibilité d’exécuter, d’étudier, de copier, d’améliorer et de redistribuer le logiciel selon vos besoins.
Inscription | GPS 43.60524/3.87336
Fiche activité:
https://montpellibre.fr/fiches_activites/Fiche_A5_017_Emission_Radio_Montpellibre_2024.pdf
- Radio FM-Plus, 4 rue Saint Barthelemy, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, radio, fm-plus, temps-libre, diffusion
Vous voulez vous engager pour une cause, rencontrer de nouvelles personnes et découvrir la cartographie participative et humanitaire? CartONG vous invite à participer à un ou plusieurs mapathons en ligne!
Au café libre - « Libre à vous ! » du 11 février 2025 - Podcasts et références
Deux-cent trente-cinquième émission « Libre à vous ! » de l’April. Podcast et programme :
- sujet principal : Au café libre, débat autour de l’actualité du logiciel libre et des libertés informatiques
- chronique Que libérer d'autre que du logiciel sur les 10 ans d'Antanak
- chronique Le truc que (presque) personne n’a vraiment compris mais qui nous concerne toutes et tous de Benjamin Bellamy, intitulée « La guerre des IA »
- quoi de Libre ? Actualités et annonces concernant l'April et le monde du Libre
Rendez‐vous en direct chaque mardi de 15 h 30 à 17 h sur 93,1 FM en Île‐de‐France. L’émission est diffusée simultanément sur le site Web de la radio Cause Commune.
Mardi 25 février 2025, notre sujet principal portera sur le réseau français des FabLabs. Si vous avez des questions, n’hésitez pas à les mettre en commentaires de cette dépêche.
- lien nᵒ 1 : Radio Cause Commune
- lien nᵒ 2 : Libre à vous !
- lien nᵒ 3 : Podcast de l'émission
- lien nᵒ 4 : Les références pour l'émission et les podcasts par sujets
- lien nᵒ 5 : S'abonner au podcast
- lien nᵒ 6 : S'abonner à la lettre d'actus
Commentaires : voir le flux Atom ouvrir dans le navigateur
GIMP 3.0 RC3 est sorti
Note : cette dépêche est une traduction de l'annonce officielle de la sortie de GIMP 3.0 RC3 du 10 février 2025 (en anglais).
Nous sommes ravis de partager la troisième version candidate de GIMP 3.0 pour ce qui (nous l'espérons) sera la dernière série de tests communautaires avant la version stable ! Cette version fait suite à la récente conférence GIMP 3 and Beyond de Jehan au FOSDEM 2025.
- Corrections de bogues et changements importants
- Améliorations
- GEGL
- Statistiques
- Autour de GIMP
- Télécharger GIMP 3.0 RC3
- Et ensuite ?
Alors que nous réduisions les quelques derniers bogues majeurs à néant, nous avons effectué un certain nombre de modifications qui selon nous nécessitent un sérieux coup d’œil de la communauté.
Jetez-en donc un, d’œil, sur les points suivants lorsque vous essayerez la Release Candidate:
Juste à temps pour GIMP 3.0, une nouvelle version de GTK3 est sortie !
Entre autres changements, GTK 3.24.48 inclut des correctifs pour plusieurs bugs affectant GIMP avec des patchs initialement fournis par Jehan, comme un crash dans Wayland lors du déplacement de calques et des problèmes de texte dans certains widgets avec des langues de droite à gauche. Nous tenons à remercier Carlos Garnacho et Matthias Clasen pour leur aide sur ces patchs respectifs.
GTK 3.24.48 ajoute également la prise en charge de la version 2 de xdg_foreign pour Wayland (la v1 reste prise en charge en tant que solution de secours). Plus précisément, l'absence de cette prise en charge provoquait le blocage de GIMP avec certaines actions sur KDE/Wayland, ce qui est désormais corrigé.
En raison de ces problèmes (certains d'entre eux rendant GIMP vraiment instable sur Wayland), nous recommandons aux empaqueteurs de mettre à jour vers la dernière version de GTK3 lors de l'empaquetage de notre RC3. Cependant, veuillez nous informer si vous remarquez des régressions ou d'autres problèmes résultant de la nouvelle version de GTK3.
Améliorations du graphe d'imagesGrâce à l'édition non destructive dans GIMP, les utilisateurs peuvent désormais empiler plusieurs filtres les uns sur les autres. Ces filtres fonctionnent généralement dans un format à haute résolution de bits, de sorte que les informations de l'image ne sont pas perdues. Cependant, la sortie de chaque filtre était convertie vers et depuis la résolution de l'image d'origine lors de l'empilement. Ainsi, si l'image n'était que de 8 bits, une grande quantité d'informations était perdue dans ces conversions constantes. Jehan a résolu ce problème en convertissant uniquement au format de l'image lorsque le filtre est censé être fusionné, plutôt que dans des piles non destructives. Comme il s'agit d'un changement important dans le fonctionnement des filtres, nous souhaitons que davantage d'utilisateurs testent ce changement pour détecter d'éventuelles régressions.
Changements dans Projection Thread-safeLorsque des modifications sont apportées à une image (comme une peinture), la projection de l'image doit être « vidée » pour afficher les nouvelles modifications à l'écran. Certains aspects de ce processus n'étaient pas « thread-safe », ce qui signifie que lorsque votre ordinateur utilisait plusieurs threads pour accélérer le travail, ils pouvaient entrer en conflit les uns avec les autres et provoquer un plantage. Cela a été observé dans notre fonctionnalité d'expansion automatique de calques. Jehan a corrigé la fonction pour qu'elle soit entièrement thread-safe. Cependant, les modifications apportées au multithreading peuvent laisser des bugs bien cachés, donc des tests communautaires supplémentaires seraient utiles.
Procédures privéesLe navigateur de base de données procédurale de GIMP montre aux développeurs de greffons et de scripts toutes les fonctions auxquelles ils peuvent accéder. Jusqu'à présent, il affichait également les fonctions « privées » qui ne sont utilisées qu'en interne. Jehan a ajouté un indicateur pour masquer ces fonctions. Dans un premier temps, nous avons ratissé trop large et caché certaines fonctions publiques importantes. Bien que nous ayons corrigé ces cas, nous aimerions que la communauté nous donne plus de détails pour nous assurer que nous n'avons oublié aucune fonction publique mal étiquetée.
AméliorationsBien que nous soyons toujours en phase de gel des fonctionnalités majeures jusqu'à la version stable de GIMP 3.0, quelques améliorations mineures et autonomes ont été apportées aux greffons.
Script-fu API FiltreLe nouvel appel PDB (gimp-drawable-merge-filter) permet aux auteurs de Script-fu d'utiliser des étiquettes pour spécifier les propriétés des filtres. Cela donnera aux utilisateurs de Script-fu la même flexibilité pour appeler et mettre à jour les filtres que les développeurs de greffons C et Python ont dans l'API GIMP 3.0. À titre d'exemple, voici un appel au filtre Emboss :
(gimp-drawable-merge-new-filter mask-emboss "gegl:emboss" 0 LAYER-MODE-REPLACE 1.0 "azimuth" 315.0 "elevation" 45.0 "depth" 7 "type" "emboss")Vous pouvez voir plus d'exemples dans notre dépôt de scripts.
Nouvelle syntaxe de passage des arguments par nomsDans Script-Fu, toutes les fonctions générées à partir de la procédure PDB des greffons doivent désormais être appelées avec une toute nouvelle syntaxe d'argument nommé, inspirée de la variante Racket de Scheme.
Par exemple, disons que votre greffon souhaite appeler le greffon Foggify, au lieu d'appeler :
(python-fu-foggify RUN-NONINTERACTIVE 1 (car (gimp-image-get-layers 1)) "Clouds" '(50 4 4) 1.0 50.0)Vous devez maintenant appeler :
(python-fu-foggify #:image 1 #:drawables (car (gimp-image-get-layers 1)) #:opacity 50.0 #:color '(50 4 4))Cela présente quelques avantages :
- des appels beaucoup plus auto-documentés, d'autant plus que certains greffons ont beaucoup d'arguments (on pouvait donc se retrouver avec des fonctions avec une douzaine d'entiers ou de flottants et c'était très déroutant) ;
- l'ordre des arguments n'a plus d'importance ;
- vous pouvez ignorer les arguments lorsque vous les appelez avec des valeurs par défaut ;
- cela permet d'améliorer les procédures des greffons dans le futur en ajoutant de nouveaux arguments sans casser les scripts existants.
Ce dernier point en particulier est important, et l'ordre des arguments n'avait plus d'importance lors de l'appel de procédures PDB depuis l'API C, ainsi que toutes les liaisons introspectées. Script-Fu était la seule interface restante dont nous disposions qui se souciait encore de l'ordre et du nombre d'arguments. Ce n'est plus le cas et c'est donc un grand pas vers une API beaucoup plus robuste pour GIMP 3 !
Formats de fichiersToutes les modifications apportées aux greffons de chargement d'images sont vérifiées avec le cadriciel de tests automatisés créé par Jacob Boerema pour éviter les régressions.
PSDEn plus des corrections de bogues telles que l'enregistrement correct des images fusionnées CMJN, Jacob Boerema a ajouté la prise en charge du chargement des fichiers PSD LAB 16 bits par canal. Il a également mis à jour la boîte de dialogue d'exportation PSD pour utiliser les fonctions d'exportation de métadonnées intégrées de GIMP.
DDSCMYK Student a implémenté la prise en charge très demandée du chargement d'images DDS avec prise en charge BC7. Jacob Boerema a travaillé pour corriger la compatibilité avec les fichiers DDS exportés à partir d'anciennes versions de GIMP.
AppImage: c'est officiel !Après neuf mois d'incubation (le nombre est une simple coïncidence
Zaibu, une alternative libre pour les amateurs de dégustation
Cette dépêche présente Zaibu, une application web auto-hébergeable permettant de conserver un journal structuré de ses dégustations de bières et de vins. Développée avec SQLPage, elle met l’accent sur la simplicité, l’indépendance et le respect de la vie privée. Contrairement aux solutions centralisées comme Untappd ou Vivino, Zaibu ne collecte aucune donnée et reste entièrement sous le contrôle de l’utilisateur.
Note : n’ayant absolument aucune compétence ni aucun talent en graphisme, le logo a été créé avec Bing Image Creator et retravaillé et vectorisé par mes soins. Je sais, çaymal.
- lien nᵒ 1 : Code source de Zaibu (AGPLv3)
- lien nᵒ 2 : SQLPage, l'outil libre de création de d'interfaces pour SQL (MIT)
- lien nᵒ 3 : Tester Zaibu en ligne
- lien nᵒ 4 : Tester SQLPage en ligne
L’alcool est dangereux pour la santé, même en petite quantité. Le vin et la bière, comme les autres alcools, induisent une dépendance et tuent. Il est recommandé de ne pas consommer plus de 2 verres par jour, et de ne pas boire d’alcool au moins 2 jours par semaine. Si vous avez des doutes sur votre consommation, n’hésitez pas à contacter un professionnel de santé.
Pourquoi créer Zaibu ?Zaibu répond avant tout à un besoin très concret : garder une trace de ses dégustations de boissons (uniquement bières et vins pour l’instant) sans dépendre d’applications trop encombrées ou propriétaires qui exploitent les données de leurs utilisateurs.
Ce projet est en fait l’évolution d’un simple fichier texte mis en forme selon une structure plus ou moins régulière. Il était à l’origine partagé via Nextcloud, un service de stockage et de synchronisation de fichiers, libre et auto-hébergeable. Pour passer de ce fichier brut à une véritable application, plusieurs outils ont été utilisés:
- Makefile : un fichier de configuration pour GNU Make, permettant d’automatiser diverses tâches (ici, la conversion du fichier texte).
- Gawk : une version libre de l’outil AWK, qui lit et transforme le contenu du fichier texte pour l’adapter au format voulu.
- textql : un utilitaire en ligne de commande qui interprète des fichiers texte (CSV, TSV…) comme des tables SQL, ce qui facilite le chargement des données dans une base SQLite.
Grâce à cette chaîne d’outils, le fichier texte initial a pu être converti en une base de données exploitable, pour ensuite alimenter l’application Zaibu.
Pour ceux qui collectionnent les bouteilles comme d’autres collectionnent les timbres, c’est un outil pratique et léger, conçu pour être maîtrisé de bout en bout : le code source est distribué sous licence libre (AGPLv3), l’application est facile à héberger sur son propre serveur, et consomme très peu de ressources.
Un objectif secondaire était de tester les capacités de l’outil SQLPage pour le développement rapide d’applications de gestion de données.
Un besoin personnelIl peut être difficile de se souvenir d’une bonne bière artisanale goûtée l’année passée ou du vin qui vous a tant plu à un mariage. Un carnet de notes ou un tableau dans un logiciel de bureautique peuvent dépanner, mais on s’y perd vite, et ce n’est pas toujours très pratique à consulter sur son téléphone quand on est en pleine dégustation.
Zaibu propose un formulaire simple où vous pouvez renseigner le nom, le producteur, le style, l’amertume, le taux d’alcool, vos impressions… Une fois la dégustation terminée, vous conservez une trace précise, consultable à tout moment. En un coup d’œil, vous pouvez comparer vos différents coups de cœur ou vous rappeler pourquoi un vin particulier ne vous avait pas convaincu.
Une occasion de tester SQLPageZaibu a aussi été conçu comme une démonstration technique. Il a servi de terrain d’expérimentation pour un nouvel outil, SQLPage, qui permet de créer une application web de gestion et d’affichage de données complète sans s’encombrer de milliers de lignes de code. En partant de requêtes de bases de données très simples, on obtient un site fonctionnel rapidement.
Ici il s’agit d’une application de type CRUD dans sa plus simple expression, donc parfaitement adaptée à être écrite en pur SQL. Même si certains traitements nécessitent de se creuser un peu plus la tête quand rien d’autre n’est disponible, il existe généralement une manière d’arriver à ses fins (et on découvre parfois avec bonheur des subtilités du langage qu’on ignorait !).
C’est le framework parfait pour créer rapidement ses propres outils tout en gardant la maîtrise complète de sa donnée, en utilisant une base de données que l’on peut héberger soi-même facilement.
Une approche libre et auto-hébergeableDe nombreuses applications existent déjà, mais elles imposent souvent la création d’un compte, exploitent les données des utilisateurs et monétisent leur activité via la publicité ou des abonnements. Zaibu prend le contre-pied en offrant une solution entièrement libre, légère et indépendante.
L’application repose sur SQLite, un système de gestion de base de données qui se distingue des bases de données traditionnelles comme MySQL ou PostgreSQL. Contrairement à ces dernières, qui nécessitent un serveur dédié fonctionnant en arrière-plan pour gérer les requêtes et stocker les informations, SQLite est une base de données embarquée.
Cela signifie que toutes les données sont enregistrées directement dans un fichier unique sur l’ordinateur ou le serveur où l’application est installée. Il n’y a donc pas besoin d’installer et de configurer un logiciel supplémentaire pour gérer la base de données. Cette approche simplifie considérablement l’installation et l’utilisation de l’application, surtout pour des utilisateurs qui ne sont pas familiers avec l’administration de serveurs.
Et puis bien sûr, son code est ouvert. C’est comme une bière artisanale : vous savez exactement quels ingrédients sont utilisés, comment ils interagissent, et si l’envie vous prend, vous pouvez modifier la recette pour l’adapter à vos préférences. Vous pouvez la brasser tel quel, y ajouter une touche personnelle, ou même la partager améliorée avec d’autres passionnés. Ici, tout est transparent et modifiable.
Une interface simple et accessiblePensée pour une utilisation mobile et desktop, l’interface de Zaibu permet d’ajouter rapidement une dégustation, sans fioritures. Sur smartphone, il devient facile de consulter ses notes en magasin ou chez un caviste pour retrouver une référence appréciée ou éviter une déception.
Et maintenant ?Zaibu est encore jeune et perfectible. L’application pourrait évoluer avec des fonctionnalités comme le partage entre utilisateurs ou l’intégration d’une base collaborative… N’hésitez pas à faire vos retours dans les commentaires !
Et si le principe vous intéresse, vous pouvez aussi découvrir Mon petit potager du même auteur et construit sur le même framework, cette fois pour suivre les récoltes de son jardin et la pluviométrie.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Revue de presse de l’April pour la semaine 7 de l’année 2025
Cette revue de presse sur Internet fait partie du travail de veille mené par l’April dans le cadre de son action de défense et de promotion du logiciel libre. Les positions exposées dans les articles sont celles de leurs auteurs et ne rejoignent pas forcément celles de l’April.
- [L'OBS] Hackathon géant: quand des étudiants s'initient à Wikipédia
- [Silicon] Souveraineté numérique: la France est-elle prête à briser ses chaînes?
- [LeDevoir.com] Pour un virage numérique libre et local
- [Le Figaro] «L'open source est l'antidote»: Roost, cette ONG qui vise à rendre gratuits des outils de modération des contenus
- [ZDNET] Comment les faux rapports de sécurité inondent les projets open-source, grâce à l'IA
- [Le Monde.fr] Protection du droit d'auteur: Thomson Reuters remporte une victoire face à une entreprise de l'IA
- [francetv info] Sommet de l'intelligence artificielle: on vous explique pourquoi la bataille de 'l'open source' menée par la France agite le secteur de l'IA
- [Next] Rust dans le noyau Linux: nouvelles bisbilles, Linus Torvalds s'en mêle
- lien nᵒ 1 : April
- lien nᵒ 2 : Revue de presse de l'April
- lien nᵒ 3 : Revue de presse de la semaine précédente
- lien nᵒ 4 :
Lettre d'information XMPP de décembre 2024
N. D. T. — Ceci est une traduction de la lettre d’information publiée régulièrement par l’équipe de communication de la XSF, essayant de conserver les tournures de phrase et l’esprit de l’original. Elle est réalisée et publiée conjointement sur les sites XMPP.org, LinuxFr.org et JabberFR.org selon une procédure définie.
Bienvenue dans la lettre d'information XMPP, ravi de vous retrouver !
Ce numéro couvre le mois de décembre 2024.
Tout comme cette lettre d'information, de nombreux projets et leurs efforts dans la communauté XMPP résultent du travail bénévole des personnes.
Si vous êtes satisfait des services et des logiciels que vous utilisez, merci de considérer dire merci ou aider ces projets !
Vous souhaitez soutenir l'équipe de la lettre d'information ? Lisez en bas de page.
- Annonces XSF
- Événements XMPP
- Conférences
- Articles XMPP
- Actualité des logiciels XMPP
- Extensions et spécifications
- Partagez les nouvelles
- Aidez-nous à construire la lettre d'information
- Licence
Si vous souhaitez rejoindre la XMPP Standards Foundation en tant que membre, postulez avant le 16 février 2025, 00h00 UTC !.
27ème Sommet XMPP et FOSDEM 2025La XSF prévoit d’organiser le 27e Sommet XMPP, qui se tiendra les 30 et 31 janvier 2025 à Bruxelles (Belgique, Europe). Après le sommet, la XSF prévoit également d’être présente au FOSDEM 2025, qui aura lieu les 1er et 2 février 2025. Retrouvez tous les détails sur notre Wiki. Inscrivez-vous dès maintenant si vous prévoyez d’y assister, cela facilite l’organisation. L’événement est bien sûr ouvert à toute personne intéressée. Faites passer l’information dans vos cercles !
XMPP au FOSDEM 2025- Présentation de Jérôme Poisson (Goffi) au FOSDEM 2025 :
-
Une API universelle et stable pour tout : XMPP :
"De nos jours, la plupart des services proposent des API avec leurs propres formats, parfois plusieurs versions, qui peuvent évoluer avec le temps. Mais il existe une API universelle, avec un excellent historique de stabilité et de compatibilité ascendante : XMPP ! Dans cette présentation, je montrerai comment XMPP peut être bien plus qu’un simple protocole de messagerie instantanée et devenir un outil extrêmement puissant pour accéder à presque tout, des réseaux tiers (messagerie, microblogging, etc.) au partage de fichiers, à l’automatisation (IoT) et bien plus encore."
La présentation aura lieu le samedi 1er février 2025, dans le cadre de la piste Communications en temps réel (RTC), salle K.3.601, de 18h25 à 18h40.
-
Une API universelle et stable pour tout : XMPP :
La XSF propose un hébergement fiscal pour les projets XMPP. Vous pouvez postuler via Open Collective. Pour plus d’informations, consultez le post de blog d’annonce. Voici les projets actuels que vous pouvez soutenir :
Événements XMPP- Berlin XMPP Meetup (DE / EN) : réunion mensuelle des passionné·e·s de XMPP à Berlin, chaque deuxième mercredi du mois à 18h (heure locale).
- Happy hour XMPP en Italie [IT] : réunion mensuelle en ligne de la communauté italienne XMPP, chaque troisième lundi du mois à 19h00 (heure locale). Événement en ligne avec mode réunion web et diffusion en direct.
- PravConf 2025 : PravConf 2025 est la première édition de la rencontre annuelle de la communauté Prav. Elle se tiendra le 1er mars 2025 au Model Engineering College, à Kochi. N’hésitez pas à rejoindre le groupe pour en savoir plus !
- Podcast : NGI0 : Next Generation Internet
- "La technologie n'est pas neutre" - Libervia : "Il est important de pouvoir communiquer librement", déclare Jérôme Poisson alias @Goffi@mastodon.social. Il est le principal développeur de Libervia, un écosystème de communication basé sur XMPP. Ce standard ouvert est principalement associé à la messagerie instantanée, mais Libervia offre bien d'autres fonctionnalités comme des blogs, des forums, des calendriers, ainsi que le partage de fichiers et de photos. Il propose des passerelles vers d'autres protocoles ouverts tels que ActivityPub et le courriel.
- Configurer XMPP (Prosody) sur Debian Bookworm : Un tutoriel pour configurer et utiliser le serveur Prosody XMPP sur Debian 12, Bookworm.
- Atom via XMPP pour les nouveaux lecteurs : XMPP comme plateforme de syndication pour les lecteurs d’actualités et autres logiciels.
- Psi+ 1.5.2069 installer a été publié.
- Conversations a publié les versions 2.17.5, 2.17.6 et 2.17.7 pour Android.
- Monal a publié les versions 6.4.7 et 6.4.8 pour iOS et macOS.
- Monocles Chat 2.0.3 a été publié pour Android. Cette version apporte des corrections, des extensions, des améliorations de l’interface utilisateur et plus encore.
- Cheogram a publié la version 2.17.2-3 pour Android. Vous pouvez désormais utiliser le partage direct, masquer les médias, les extensions, et bien plus.
- Kaidan a publié la version 0.10.0 avec tant de fonctionnalités qu’elles ne peuvent pas être résumées en une seule phrase ! Vous trouverez une liste complète des modifications dans la section des changements ainsi qu’un aperçu technique de toutes les fonctionnalités actuellement prises en charge. La version 0.10.1 a été publiée quelques jours plus tard avec des corrections de bugs.
- ProcessOne annonce ejabberd 24.12 : La version "evacuate_kindly" : comprenant quelques améliorations et corrections de bugs, cette version arrive un mois et demi après la version 24.10, avec environ 60 commits dans le dépôt principal ainsi que quelques mises à jour des dépendances.
- Prosody IM est heureux d’annoncer la sortie de la version 0.12.5, une nouvelle mise à jour mineure de la branche stable 0.12. Comme toujours, vous pouvez consulter le journal des modifications pour cette version ainsi que les instructions de téléchargement pour de nombreuses plateformes sur leur page de téléchargement.
- La version 1.9.2 de QXmpp a été publiée.
- Les versions 0.2.8 et 0.2.9 de go-xmpp ont été publiées.
- Les versions 0.13.0 et 0.14.0 de go-sendxmpp ont été publiées.
La XMPP Standards Foundation développe des extensions pour XMPP dans sa série XEP en plus des RFC XMPP.
Des développeuses, développeurs et experts en standards du monde entier collaborent sur ces extensions, en élaborant de nouvelles spécifications pour des pratiques émergentes et en affinant des méthodes existantes. Proposées par n’importe qui, celles qui rencontrent un grand succès deviennent Finales ou Actives, selon leur type, tandis que d’autres sont soigneusement archivées comme Reportées. Ce cycle de vie est décrit dans XEP-0001, qui contient les définitions formelles et canoniques des types, états et processus. En savoir plus sur le processus des standards. La communication autour des standards et des extensions a lieu sur la liste de diffusion des standards (archive en ligne).
Extensions proposéesLe processus de développement des XEP commence par la rédaction d’une idée et sa soumission à l’éditeur XMPP. Dans un délai de deux semaines, le Conseil décide d’accepter ou non cette proposition comme une XEP expérimentale.
- Aucune XEP proposée ce mois-ci.
- Version 0.1.0 de XEP-0501 (Histoires Pubsub).
- Promue à Expérimental (Éditeur XEP : dg)
- Version 0.1.0 de XEP-0502 (Indicateur d’activité MUC).
- Promue à Expérimental (Éditeur XEP : dg)
Si une XEP expérimentale n’est pas mise à jour pendant plus de douze mois, elle sera retirée de la catégorie Expérimental pour être classée comme Déférée. Si une mise à jour intervient, la XEP sera replacée dans la catégorie Expérimental.
- Aucune XEP déférée ce mois-ci.
- Version 0.2.0 de XEP-0480 (Tâches de mise à niveau SASL).
- Correction de la description de la mise à niveau SCRAM et du schéma XML. (tm)
- Version 0.1.1 de XEP-0500 (Mode lent pour MUC).
- Intégration des premiers retours. (jl)
- Version 0.2.0 de XEP-0501 (Histoires Pubsub).
- Ajout de pubsub#item_expire dans la configuration du nœud. (tj)
Les derniers appels sont émis une fois que tout le monde semble satisfait de l’état actuel de la XEP. Après que le Conseil ait jugé la XEP prête, l’éditeur XMPP lance un dernier appel pour recueillir des commentaires. Les retours collectés pendant cet appel peuvent améliorer la XEP avant qu’elle ne soit renvoyée au Conseil pour son passage au statut Stable.
- Dernier appel pour commentaires sur XEP-0421 (Identifiants anonymes uniques pour les occupant·e·s des MUCs).
- Ce dernier appel se terminera à la fin de la journée du 6 janvier 2025.
- Dernier appel pour commentaires sur XEP-0424 (Rétraction de message).
- Ce dernier appel se terminera à la fin de la journée du 6 janvier 2025.
- Aucune XEP n’a été déplacée au statut Stable ce mois-ci.
- Aucune XEP n’a été dépréciée ce mois-ci.
- Aucune XEP n’a été rejetée ce mois-ci.
Veuillez partager ces nouvelles sur d'autres réseaux :
- Mastodon
- YouTube
- Instance Lemmy (non officiel)
- Reddit (non officiel)
- Page Facebook XMPP (non officielle)
Consultez également notre flux RSS !
Vous recherchez des offres d’emploi ou souhaitez engager une personne en tant que consultante professionnelle pour votre projet XMPP ? Consultez notre tableau des offres d’emploi XMPP.
Contributions et traductions de la lettre d'informationIl s’agit d’un effort communautaire, et nous souhaitons remercier les bénévoles pour leurs contributions. Le bénévolat et les traductions dans d'autres langues sont les bienvenus ! Les traductions de la lettre d'information XMPP seront publiées ici (avec un certain délai) :
- Anglais (original) : xmpp.org
- Contributions générales : Adrien Bourmault (neox), Alexander "PapaTutuWawa", Arne, cal0pteryx, emus, Federico, Gonzalo Raúl Nemmi, Jonas Stein, Kris "poVoq", Licaon_Kter, Ludovic Bocquet, Mario Sabatino, melvo, MSavoritias (fae,ve), nicola, Schimon Zachary, Simone Canaletti, singpolyma, XSF iTeam
- Français : jabberfr.org et linuxfr.org
- Traductions : Adrien Bourmault (neox), alkino, anubis, Arkem, Benoît Sibaud, mathieui, nyco, Pierre Jarillon, Ppjet6, Ysabeau
- Italien : notes.nicfab.eu
- Traductions : nicola
- Espagnol : xmpp.org
- Traductions : Gonzalo Raúl Nemmi
- Allemand : xmpp.org
- Traductions : Millesimus
Cette lettre d'information XMPP est produite de manière collaborative par la communauté XMPP. Chaque numéro mensuel de la lettre d'information est rédigé dans ce pad simple. À la fin de chaque mois, le contenu du pad est fusionné dans le dépôt GitHub de l’XSF. Nous sommes toujours ravis d'accueillir des contributions. N’hésitez pas à rejoindre la discussion dans notre chat de groupe Comm-Team (MUC) et à nous aider à maintenir cet effort communautaire. Vous avez un projet et souhaitez partager vos actualités ? Pensez à partager vos nouvelles ou événements ici pour les promouvoir auprès d’un large public.
Tâches que nous réalisons régulièrement :
- recueillir des nouvelles dans l’univers XMPP
- rédiger des résumés brefs des actualités et événements
- résumer les communications mensuelles sur les extensions (XEPs)
- réviser le brouillon de la lettre d'information
- préparer des images pour les médias
- traduire
- communiquer via les comptes sur les réseaux sociaux
Cette lettre d'information est publiée sous la licence CC BY-SA.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Nouvelles de Haiku - Hiver 2024-25
Haiku est un système d’exploitation pour les ordinateurs personnels. Il s’agit à l’origine d’une réécriture de BeOS. Le projet a démarré en 2001 et est actuellement en phase de beta-test pour une première version stable avec support à long terme. Depuis 2024, l’activité du projet Haiku s’accélère grâce entre autres à l’embauche d’un développeur à plein temps. Les dépêches sur Haiku sont donc désormais publiées tous les 3 mois au lieu de tous les ans pour leur conserver une longueur digeste.
La complète liste des changements survenus pendant ces 3 mois comporte près de 300 commits. La dépêche ne rentre pas dans les détails de chaque changement et met en valeur les plus importants.
Les grosses évolutions sont un nouveau port de Iceweasel (Firefox), et des grosses améliorations sur la gestion de la mémoire.
Comme on est en début d’année, c’est aussi le moment du bilan financier.
- lien nᵒ 1 : Rapport d'activité de novembre 2024
- lien nᵒ 2 : Repport d'activté de décembre 2024
- lien nᵒ 3 : Rapport d'activité de janvier 2025
- Rapport financier 2024
- Applications
- Kits
- Servers
- Drivers
- Systèmes de fichiers
- libroot
- Kernel
- Chargeur de démarrage
- Outils de compilation
- Documentation
- Traductions de Haiku
L’association Haiku inc (association de type 501(c)3 aux USA) publie chaque année un rapport financier. Le rôle de l’association est de récolter les dons et de les redistribuer pour aider au développement de Haiku. Elle ne prend pas part aux décisions techniques sur l’orientation du projet, et habituellement les dépenses sont faites en réponse aux demandes des développeurs du projet.
L’objectif en début d’année 2024 était de récolter 20 000$ de dons. Cet objectif a été largement atteint, il a dû être mis à jour 2 fois en cours d’année et finalement ce sont plus de 31 000$ qui ont été reçus ! Cela en particulier grace à un assez gros don de 7 500$.
Les dons sont récoltés via différentes plateformes: Github Sponsors (intéressant, car il n’y a aucun frais de traitement), PayPal, Liberapay, Benevity (une plateforme de « corporate matching »), ainsi que des paiements par chèque, virements bancaires, et en espèce lors de la tenue de stands dans des conférences de logiciels libres. La vente de T-Shirts et autre merchandising via la boutique Freewear reste anecdotique (une centaine de dollars cette année).
Il faut ajouter à ces dons une contribution de 4 400$ de la part de Google en compensation du temps passé à l’encadrement des participants au Google Summer of Code.
Il faut également ajouter des dons en crypto-monnaies, principalement en bitcoins. Le rapport financier présente les chiffres en détail en tenant une compatibilité séparée en dollars, en euros, et en crypto-monnaies, avant de convertir le total en dollars pour dresser un bilan complet.
Une mauvaise nouvelle tout de même: le service de microdons Flattr a fermé ses portes. L’entreprise propose maintenant un service de bloqueur de publicités payant, qui reverse de l’argent aux sites dont les publicités sont bloquées.
Le compte Flattr de Haiku avait été créé pour recevoir des dons sur la plateforme, mais n’avait jamais été configuré pour transférer ces dons vers le compte en banque de l’association. Malgré un certain temps passé à discuter avec le service client de Flattr et à leur fournir tous les documents demandés, il n’a pas été possible de trouver une solution pour récupérer cet argent. Ce sont donc 800$ qui ne reviendront finalement pas au projet Haiku.
Au final, les recettes sont de 36 479 dollars, de loin la plus grosse somme reçue par le projet en un an.
DépensesLa dépense principale est le paiement de Waddlesplash, le développeur actuellement employé par Haiku inc pour accélérer le développement du système (les autres développeurs participent uniquement sur leur temps libre, en fonction de leurs autres activités). Cela représente 25 500$, un coût assez faible par rapport au travail réalisé.
Le deuxième poste de dépenses est l’infrastructure, c’est-à dire le paiement pour l’hébergement de serveurs, les noms de domaines, et quelques services « cloud » en particulier pour le stockage des dépôts de paquets.
Le reste des dépenses consiste en frais divers (commission PayPal par exemple), remboursement de déplacements pour la participation à des conférences, ainsi que le renouvellement de la marque déposée sur le logo Haiku.
Le total des dépenses s’élève à 31 467$. C’est moins que les recettes, et l’association continue donc de mettre de l’argent de côté. L’année 2022 a été la seule à être déficitaire, suite au démarrage du contrat de Waddlesplash. Ce contrat est à présent couvert par les donations reçues.
RéservesL’association dispose de plus de 100 000$ répartis sur son compte en banque, un compte PayPal (qui permet de conserver des fonds en euros pour les paiements en euros et ainsi d’éviter des frais de change), et un compte Payoneer (utilisé pour recevoir les paiements de Google).
Elle dispose également de près de 350 000$ en crypto-monnaies dont la valeur continue d’augmenter. Cependant, actuellement ces fonds ne sont pas accessibles directement, en raison de problèmes administratifs avec Coinbase, l’entreprise qui gère ce portefeuille de crypto-monnaies. Le compte n’est pas configuré correctement comme appartenant à une association à but non lucratif et cela pose des problèmes de déclaration de taxes lorsque on souhaite vendre des crypto-monnaies contre du vrai argent. Cette situation persiste depuis plusieurs années, mais l’association n’a pour l’instant pas besoin de récupérer cet argent, les réserves dans le compte en banque principal étant suffisantes.
Applications IceweaselLe navigateur web Iceweasel est disponible dans les dépôts de paquets (seulement pour la version 64 bits pour l’instant). Il s’agit d’un portage de Firefox utilisant la couche de compatibilité Wayland. Le nom Firefox ne peut pas être utilisé puisqu’il ne s’agit pas d’un produit officiel de Mozilla.
En plus du travail de portage pour réussir à faire fonctionner le navigateur, cela a nécessité un gros travail d’amélioration au niveau de la gestion de la mémoire, une partie du système qui est fortement mise à contribution par ce navigateur. On en reparle plus loin dans la dépêche.
Le navigateur est encore considéré comme expérimental: plusieurs fonctions sont manquantes et il peut y avoir des plantages. WebPositive (le navigateur natif basé sur WebKit) reste donc le navigateur installé par défaut avec Haiku, mais les deux sont complémentaires. Par exemple, Iceweasel permet d’afficher les vidéos Youtube avec des performances acceptables.
TrackerTracker est le gestionnaire de fichiers de Haiku. Il implémente une interface « spatiale », c’est-à-dire que chaque dossier s’ouvre dans une fenêtre séparée et enregistre sa position à l’écran.
Le code du Tracker fait partie des composants qui ont pu être récupérés de BeOS. Cela signifie que certaines parties du code ont été développées il y a près de 30 ans, dans un contexte où l’élégance du code n’était pas la priorité (il fallait pour les développeurs de BeOS, d’une part livrer un système fonctionnel dans un temps raisonable, et d’autre part, fonctionner sur les machines relativement peu performantes de l’époque).
Les évolutions sur le Tracker nécessitent donc souvent du nettoyage dans de nombreuses parties du code, et provoquent souvent des régressions sur d’autres fonctionnalités. Toutefois, les choses s’améliorent petit à petit.
Ce trimestre, on a vu par exemple arriver la correction d’un problème avec l’utilisation de la touche « echap ». Cette touche peut servir à plusieurs choses:
- Fermer une fenêtre de chargement ou d’enregistrement de fichier,
- Annuler le renommage d’un fichier,
- Annuler une recherche rapide « type ahead » qui consiste à taper quelques lettres et voir immédiatement la liste de fichiers du dossier courant se réduire à ceux qui contiennent cette chaîne de caractères.
Ces différentes utilisations peuvent entrer en conflit. Plus précisément, lorsqu’on utilise le filtrage « type ahead », puis qu’on change d’avis et qu’on appuie sur la touche « echap », il ne faut pas que cela ferme la fenêtre en même temps.
Un autre changement concerne plutôt la validation des données: Tracker interdit l’insertion de caractères de contrôle ASCII dans le nom de fichiers. Ce n’est pas strictement interdit (ni par Haiku, ni par ses systèmes de fichiers, ni par POSIX) en dehors de deux caractères spéciaux: le '/' et le 0 qui termine une chaîne de caractères. Mais, c’est très probablement une mauvaise idée d’avoir un retour à la ligne ou un autre caractère de contrôle enregistré dans un nom de fichier. Le Tracker interdit donc désormais de le faire et si vous êtes vraiment résolu à y parvenir, il faudra passer par le terminal.
Enfin, une nouvelle fonctionnalité dans le Tracker est la mise à jour en temps réel des menus pop-up. Cela peut se produire pour plusieurs raisons, par exemple, l’appui sur la touche « command » modifie le comportement de certains menus. Avant ce changement, il fallait ré-ouvrir le menu (command + clic droit) pour voir ces options modifiées. Maintenant, on peut d’abord ouvrir le menu, puis maintenir la touche command enfoncée pour voir les options modifiées.
Cela a nécessité une refonte complète de la gestion de ces menus (qui proposent de nombreuses autres choses comme la navigation « rayons X »). Au passage, certaines options qui étaient uniquement disponibles au travers de raccourcis claviers ou de la barre de menu des fenêtres du Tracker sont maintenant aussi affichées dans le menu pop-up.
TeamMonitorTeamMonitor est le gestionnaire d’applications affiché quand on utilise la combinaison de touches Ctrl+Alt+Suppr. Il permet de stopper des programmes, de redémarrer la machine, et autres manipulations d’urgence si le système ne fonctionne pas comme il faut.
Les processus lancés par une même application sont maintenant regroupés et peuvent être tous arrêtés d’un seul coup. Ce changement est nécessaire suite à l’apparition de IceWeasel, qui crée beaucoup de processus en tâche de fond pour une seule instance du navigateur web.
HaikuDepotHaikuDepot est l’interface graphique pour le système de paquets de Haiku. Il se présente comme un magasin d’applications, permettant non seulement d’installer et de désinstaller des logiciels, mais aussi de les évaluer avec une note et un commentaire.
- Ajout d’un marqueur sur les icônes des paquets qui sont déjà installés, et remplacement du marqueur utilisé pour indiquer les applications « natives » (utilisant le toolkit graphique de Haiku, par opposition à Qt et GTK par exemple).
- Affichage plus rapide de l’état « en attente d’installation » lorsqu’on demande l’installation d’un paquet.
- L’interface pour noter un paquet est masquée si l’attribution de notes n’est pas possible.
Diverses améliorations dans les fenêtres de préférences:
- Correction d’un crash dans les préférences d’affichage (korli).
- Les préférences de fond d’écran n’acceptent plus le glisser-déposer d’une couleur sur un contrôle de choix de couleur désactivé. La modification de la position X et Y de l’image de fond se met à jour en temps réel quand on édite la valeur des contrôles correspondants.
- Ajout de réglages supplémentaires (vitesse, accélération, défilement) dans les préférences des pavés tactiles. Ces options étaient déjà implémentées dans l’input_server, mais configurable uniquement pour les souris.
- Suppression de code mort et amélioration de la gestion des polices de caractères dans les préférences d’apparence.
Plusieurs améliorations sur les préférences de sons de notifications:
- La fenêtre de sélection de fichiers retient le dernier dossier utilisé,
- Elle permet également d’écouter un son avant de le sélectionner,
- Les menus de sélection rapide de sons affichent uniquement les fichiers et pas les dossiers,
- Certains sons ont été renommés.
La plupart des sons ne sont cependant toujours pas utilisés par le système.
ExpanderExpander est un outil permettant d’extraire plusieurs types de fichiers archivés.
Peu de changement sur cet outil qui est assez simple et fonctionnel. La seule amélioration ce mois-ci concerne un changement des proportions de la fenêtre pour éviter un espace vide disgracieux.
CortexCortex est une application permettant de visualiser et de manipuler les nœuds de traitement de données du Media Kit.
Le composant « logging consumer » qui reçoit des données d’un autre noeud et les enregistre dans un fichier de log pour analyse a été amélioré pour enregistrer un peu plus d’informations.
Icon-O-MaticL’éditeur d’icônes vectoriels Icon-O-Matic évolue peu, après un projet Google Summer of Code qui a ajouté la plupart des fonctionnalités manquantes. Ce trimestre, un seul changement: l’ajout d’une entrée menu pour supprimer un « transformeur ».
PowerStatusL’application PowerStatus affiche l’état de la batterie. Cela peut se présenter comme une icône dans la barre des tâches. L’icône est de taille réduite, et les différents états n’étaient pas forcément bien visibles. Ce problème a été corrigé avec des nouveaux marqueurs pour l’état de la batterie (en charge ou inactive).
StyledEditStyledEdit est un éditeur de texte simple, permettant tout de même de formater le texte (un peu comme WordPad pour Windows).
L’application reçoit une nouvelle option pour écrire du texte barré. Le code nécessaire a également été ajouté dans app_server, puisque cette possibilité était prévue, mais non implémentée.
WebPositiveLe navigateur WebPositive reçoit peu d’évolutions en ce moment, en dehors de la maintenance du moteur WebKit. On peut tout de même mentionner l’ajout d’un menu contextuel sur les marque-pages, permettant de les renommer et de les supprimer. Ce développement est issu d’un vieux patch réalisé par un candidat au Google Summer of Code, qui ne fonctionnait pas et n’avait jamais été finalisé.
Mode sombre et configuration des couleursDepuis la version Beta 5, Haiku dispose d’un nouveau système de configuration des couleurs, permettant d’obtenir facilement un affichage en « mode sombre ». Cependant, cet affichage est loin d’être parfait, et de petits ajustements sont à faire petit à petit dans toutes les applications qui n’avaient pas été pensées pour cela. En particulier, le changement de couleurs se fait en direct lorsqu’on change les réglages. On trouve ces trois derniers mois des changements dans DeskBar, Tracker, HaikuDepot, l’horloge, ainsi que la classe BTextView.
Outils en ligne de commandepkgman peut rechercher les paquets installés et qui n’ont aucun autre paquet dépendant d’eux. Cela permet de trouver des paquets inutiles qui peuvent être désinstallés (il manque encore la possibilité de marquer un paquet comme étant « installé manuellement » avant de pouvoir automatiser le nettoyage).
La commande route accepte la syntaxe utilisée par openvpn pour la configuration d’une route par défaut, ce qui facilite l’utilisation de VPN avec Haiku.
Correction d’un problème dans le compilateur de ressources: la commande rc -d ne savait pas décompiler la structure app_version des applications Haiku, uniquement le format plus ancien utilisé par BeOS.
La commande screenmode permet maintenant de récupérer la valeur actuelle du réglage du rétro-éclairage (en plus de permettre de changer cette valeur).
KitsLa bibliothèque de fonctions de Haiku est découpée en « kits » qui regroupent un ensemble de classes et de fonctionnalités liées.
Application kitL’Application Kit permet, comme son nom l’indique, de lancer des applications. Il offre également toutes les fonctionnalités de boucles d’évènements, et d’envoi de messages entre applications et entre composants d’une application.
Correction d’un problème de suppression d’un port dans la classe BApplication.
Debug kitLe Debug Kit fournit les services nécessaires au Debugger pour débugger une application. Cela consiste d’une part en un accès privilégie à l’espace mémoire d’une application, et d’autre part en outils pour analyser les fichiers ELF des exécutables et bibliothèques.
Le Debug Kit reçoit ce trimestre plusieurs évolutions et corrections permettant le décodage des stack traces dans les programmes compilés avec clang et lld. Par exemple, les fichiers ELF générés par ces outils sont découpés en plusieurs segments, alors que ce n’est pas le cas pour gcc.
Device KitLe Device Kit regroupe tout ce qui concerne l’accès direct au matériel et aux entrées-sorties depuis l’espace utilisateur: ports série, accès direct aux périphériques USB, accès aux joysticks et manettes de jeu.
Les ports série RS232 peuvent être configurés avec des valeurs en baud personnalisées (pour l’instant uniquement pour les adaptateurs série USB).
Interface kitL’Interface Kit regroupe tout ce qui concerne l’affichage de fenêtres et de vues à l’écran et les interactions avec ces fenêtres.
- Ajout de constructeur « move » et d’opérateur d’assignation pour BRegion et BShape pour améliorer les performances en évitant les copie d’objet immédiatement suivies de suppression.
- Ajout d’un constructeur pour BRect avec deux arguments (largeur et hauteur) pour les rectangles alignés en haut à gauche ou dont la position n’a pas d’importance.
- Remise en place d’un cas particulier dans BBitmap::SetBits pour la gestion du canal alpha afin d’avoir un comportement plus proche de celui de BeOS.
- BColorControl réagit correctement et déclenche les évènements nécessaires lorsqu’on modifie sa couleur par glisser-déposer.
Correction d’une assertion vérifiant la mauvaise condition dans BTimeSource.
Réécriture de la classe BTimedEventQueue pour améliorer ses performances en évitant d’allouer de la mémoire dynamique.
Amélioration de l’affichage des « media controls » (sliders de contrôle de volume par exemple) en mode sombre.
libsharedLa « libshared » contient plusieurs classes expérimentales, en cours de développement, mais déjà utilisées par plusieurs applications. Il s’agit d’une bibliothèque statique, ce qui permet de changer facilement son contenu sans casser l’ABI des applications existantes.
Ajout de la classe ColorPreview qui existait en plusieurs exemplaires dans le code de Haiku (préférences d’apparence et Terminal). Cette classe permet d’afficher une couleur dans un petit rectangle. Elle est utilisée à plusieurs endroits dans des contrôles de choix de couleur plus complexes, tels que des listes ou des menus.
ServersLes servers sont des processus systèmes implémentant différentes fonctionnalités de Haiku. Le concept est similaire à celui des daemons dans UNIX, ou des services dans Windows NT et systemd.
app_serverL’app_server s’occupe de l’affichage des applications à l’écran.
Suppression de code inutilisé depuis longtemps permettant l’accélération matérielle d’opérations de dessin en 2D (blit, tracé de lignes, remplissage de rectangles…).
Sur les cartes graphiques PCI, ces opérations étaient souvent réalisées plus rapidement par le CPU qui tourne à une fréquence bien plus rapide que la carte. Sur les cartes AGP, l’accès en lecture à la mémoire vidéo par le CPU est très lent, et il était donc plus intéressant de faire ces opérations en RAM centrale avant d’envoyer un buffer prêt à afficher à la carte graphique. Enfin sur les cartes PCI express modernes, ces fonctions d’accélération ont disparu ou en tout cas n’ont pas du tout une interface compatible avec les besoins de Haiku. Il est donc temps de jeter ce code.
Modification de la façon dont les applications récupèrent la palette de couleurs en mode graphique 256 couleurs: elle utilise maintenant une mémoire partagée, et il n’est plus nécessaire que chaque application demandent au serveur graphique d’en obtenir une copie.
input_serverL’input_server se charge des entrées souris et clavier. Cela comprend les méthodes d’entrée de texte (par exemple pour le Japonais) ainsi que des filtres permettant de manipuler et d’intercepter ces évènements d’entrée avant leur distribution dans les applications.
Améliorations du filtre PadBlocker pour bloquer le touchpad quand le clavier est en cours d’utilisation sur les PC portables: gestion des répétitions de touches, blocage uniquement du touchpad et pas des autres périphériques de pointage.
net_serverLe net_server se charge de la configuration des interfaces réseau.
Arrêt du client d’autoconfiguration (DHCP par exemple) lors de la perte du lien sur un port Ethernet, pour ne pas essayer d’envoyer des paquets alors que le câble est débranché.
notification_servernotification_server se charge de l’affichage de panneaux de notification pour divers évènements tels que la connexion et déconnexion d’interfaces réseau, un niveau dangereusement bas de la batterie, la fin d’un téléchargement…
La fenêtre de notification a été retravaillée pour mieux s’adapter à la taille de police d’affichage choisie par l’utilisateur.
mail_daemonmail_daemon permet d’envoyer et de recevoir des e-mails. Les messages sont stockés sous forme de fichiers avec des attributs étendus pour les métadonnées (sujet, expéditeur…). Plusieurs applications clientes permettent de rédiger ou de lire ces fichiers. Ainsi chaque application n’a pas besoin de réimplémenter les protocoles IMAP ou SMTP.
Amélioration de la fenêtre de logs pour la compatibilité avec le mode sombre.
runtime_loaderLe runtime_loader est l’outil qui permet de démarrer un exécutable. Il se charge de trouver toutes les bibliothèques partagées nécessaires et de les placer dans la mémoire.
Ajout du flag PF_EXECUTE qui rend exécutable uniquement les sections ELF qui le nécessitent (auparavant, toutes les sections qui n’étaient pas accessibles en écriture étaient exécutables). Cela est utilisé en particulier par clang, qui sépare une zone en lecture seule (pour les constantes) et une autre en lecture et exécution (pour le code). Avec gcc, les deux sont habituellement regroupées dans la même section.
Drivers Périphériques de stockageCorrection de bugs dans la couche SCSI (utilisée également pour d’autres périphériques de stockage qui encapsulent des commandes SCSI). Des drapeaux d’état n’étaient pas remis à 0 au bon moment, ce qui causait des kernel panic avec le message « no such range! ».
Cela a été l’occasion de faire du ménage : suppression de champs inutilisés dans des structures de données, et suppression du module d’allocation mémoire locked_pool qui n’était utilisé que par la pile SCSI. À la place, utilisation des fonctions d’allocation mémoire standard du noyau, qui sont amplement suffisantes pour répondre aux besoins de ce module (waddlesplash).
Cartes sonCorrection d’erreurs dans le code de gestion mémoire des pilotes es1370 et auvia. Ces drivers utilisaient deux copies d’un code d’allocation identique, mais avaient divergé l’un de l’autre. Ils ont été réunifiés mais cela a provoqué quelques régressions, avec des difficultés pour trouver des machines permettant de tester chacune des cartes son concernées. Haiku peut heureusement compter sur des utilisateurs « avancés » qui testent régulièrement les nightly builds pour détecter ce type de régression (korli).
RéseauCorrection d’une fuite mémoire lors de l’utilisation de sockets « raw » permettant d’envoyer et de recevoir directement des paquets ethernet (en contournant la couche IP).
Pilotes FreeBSDUne grande partie des pilotes de carte réseau de Haiku sont en fait ceux de FreeBSD ou d’OpenBSD. Une couche de compatibilité permet de réutiliser ces pilotes avec très peu de changement dans leur code source. Ainsi, les évolutions et corrections peuvent être partagées avec l’un ou l’autre de ces systèmes. La collaboration avec les *BSD pour les pilotes réseau se passe de mieux en mieux : suite au développement d’une couche de compatibilité permettant d’utiliser les pilotes OpenBSD dans Haiku, les développeurs de FreeBSD étudient la possibilité de réutiliser également ces pilotes. De plus, les développeurs de Haiku et d’OpenBSD sont en contact pour coordonner les mises à jour et les tests.
Génération de statistiques plus fiables sur les paquets réseaux dans la couche de compatibilité FreeBSD et remontée des statistiques générées par les pilotes associés.
Synchronisation du pilote realtekwifi avec la version de FreeBSD et reconnaissance d’un identifiant de périphérique USB supplémentaire dans ce pilote.
Amélioration de la couche de compatibilité pour se comporter plus précisément comme FreeBSD, et suppression de patchs correspondants dans les pilotes qui sont devenus superflus.
Amélioration des performances de la couche de compatibilité: retrait de comparaisons de chaînes de caractères et d’allocations inutiles.
Pilotes spécifiques à HaikuAmélioration du comportement du pilote USB RNDIS (partage de connexion sur USB de certains téléphones Android) lorsque le câble USB est déconnecté. Le pilote incluait du code pour tenter de restaurer la connexion existante si le même appareil est reconnecté, mais les périphériques RNDIS utilisent des adresses MAC aléatoires qui changent à chaque connexion, donc cela ne pouvait pas fonctionner. De plus, certains transferts USB n’étaient pas correctement annulés pour laisser la pile USB dans un état propre après la déconnexion du périphérique.
USBAjout d’une annulation de transferts de données en attente dans le pilote pour les périphériques de stockage USB, ce qui corrige un kernel panic lors de l’utilisation de lecteurs de disquettes USB. Arrêt immédiat des opérations (au lieu de ré-essayer pendant quelques secondes) si le périphérique indique « no media present » (CD ou disquette éjectée de son lecteur par exemple).
Ajout d’une vérification de pointeur NULL et de libération de mémoire manquantes dans la pile USB, ce qui corrige des fuites de mémoires (qui étaient là depuis longtemps) et une assertion qui se déclenchait (introduite plus récemment).
Le pilote de webcam UVC est mis à jour pour utiliser des constantes (identifiants de types de descripteurs…) partagées avec le reste du système au lieu de toutes les redéfinir une deuxième fois. L’affichage des descripteurs dans listusb est également complété pour décoder toutes les informations disponibles. Le pilote n’est toujours pas complètement fonctionnel: l’établissement des transferts au niveau USB fonctionne, mais pour l’instant le pilote ne parvient pas à décoder les données vidéo reçues correctement.
Le pilote HID sait reconnaître les « feature reports », qui permettent de configurer un périphérique. Par exemple, cela peut permettre de configurer un touchpad en mode multi-point (dans lequel le système doit effectuer lui-même le suivi de chaque doigt sur la surface tactile pour convertir cela en mouvements de pointeur de souris) ou en mode émulation de souris (où on ne peut utiliser qu’un doigt à la fois, mais avec un pilote beaucoup plus simple).
Le pilote pour les tablettes Wacom reconnaît la tablette CTH-470.
PS/2Les ports PS/2 ont disparu de la plupart des machines ces dernières années, mais le protocole reste utilisé pour le clavier des ordinateurs portables, ainsi que pour certains touchpads. Malheureusement, le protocole est seulement émulé au niveau de l’« embedded controller » (le microprocesseur qui se charge de l’interfaçage de divers composants annexes). Le résultat est que l’implémentation du protocole et des registres d’interface peut s’éloigner considérablement des documents officiels.
Amélioration de la détection des contrôleurs PS/2 supportant le protocole « active multiplexing » permettant de connecter à la fois une souris et un touchpad. La procédure de détection officielle peut générer des faux positifs: certains contrôleurs répondent bien à cette commande, mais n’implémentent en fait pas du tout le protocole. Cela provoquait un long délai au démarrage alors que le pilote tente d’énumérer des périphériques de pointage qui n’existent pas. Une vérification supplémentaire après l’activation du mode multiplexé permet de détecter ce cas.
virtio_pcivirtio est un standard matériel pour les machines virtuelles. Plutôt que d’émuler un vrai matériel (carte réseau, carte graphique…), une machine virtuelle peut émuler un matériel qui n’a jamais été fabriqué, mais dont la programmation est beaucoup plus simple. Cela permet également des opérations inimaginables sur du matériel réel, comme la possibilité de changer la taille de la RAM en cours d’exécution pour mieux partager la mémoire de l’hôte entre différentes machines virtuelles.
Le pilote virtio_pci est à la racine du système virtio. Il détecte la « carte PCI » virtio et implémente les primitives de base d’envoi et de réception de messages entre l’hôte et la machine virtualisée (du côté virtualisé, pour le côté hôte, c’est le virtualisateur, par exemple QEMU, qui s’en charge).
Correction de plusieurs problèmes avec les numéros de files virtio qui rendaient les pilotes instables.
ACPIACPI est un cadriciel pour la gestion de l’énergie et l’accès au matériel. Le fabricant du matériel fournit (dans la ROM du BIOS) un ensemble de « tables » contenant une description du matériel disponible, ainsi que des méthodes compilées en bytecode pour piloter ce matériel. Le système d’exploitation doit fournir un interpréteur pour ce bytecode, puis réaliser les entrées-sorties vers le matériel demandé lors de l’exécution.
Haiku utilise actuellement ACPICA, une bibliothèque ACPI développée principalement par Intel.
Correction d’un problème d’accès à de la mémoire non cachée. Une modification faite pour les machines ARM a déclenché un problème sur les machines x86.
Sondes de températureAjout d’un nouveau pilote amd_thermal, ajout de ce dernier ainsi que des pilotes pch_thermal et acpi_thermal dans l’image disque par défaut. Ces pilotes devraient permettre de récupérer la température du processeur sur la plupart des machines. Il reste maintenant à intégrer cela dans les outils en espace utilisateur pour faire un bon usage de ces informations.
Pilotes graphiquesAjout de deux nouvelles générations de cartes graphiques dans le pilote intel_extreme.
Le pilote VESA est capable de patcher le BIOS de certaines cartes graphiques à la volée pour y injecter des modes graphiques supplémentaires (la spécification VESA permettant à l’OS uniquement de choisir un mode parmi une liste fournie par la carte graphique, liste souvent assez peu fournie). Ce mode est désormais activé par défaut sur les cartes graphiques où il a pu être testé avec succès.
Systèmes de fichiers FATFAT est un système de fichier développé par Microsoft et qui remonte aux premiers jours de MS-DOS. Il est encore utilisé sur certaines clés USB et cartes SD, bien que exFAT tend à le remplacer petit à petit. Il est également utilisé pour les partitions systèmes EFI.
Le pilote de Haiku a été récemment réécrit à partir de celui de FreeBSD. L’amélioration de ce nouveau pilote se poursuit, avec ce mois-ci :
- Les noms de volumes FAT sont convertis en minuscules comme le faisait l’ancien pilote FAT,
- Le cache de blocs implémente maintenant un mécanisme de prefetch pour récupérer plusieurs blocs disque d’un coup, et le pilote FAT utilise cette nouvelle possibilité pour améliorer en particulier le temps de montage,
- Correction de problèmes dans le cache de fichiers si deux applications accèdent au même fichier mais avec des noms différents par la casse (le système de fichier ignorant ces différences).
BFS est le système de fichier principal de BeOS et de Haiku. Il se distingue des autres systèmes de fichiers par une gestion poussée des attributs étendus, avec en particulier la possibilité de les indexer et d’effectuer des requêtes pour trouver les fichiers correspondants à certains critères.
Clarification de la description des options disponibles lors de l’initialisation d’un volume BFS.
Correction des fonctions d’entrées/sorties asynchrones pour référencer correctement les inodes, ce qui corrige un très ancien rapport de bug. Des corrections similaires ont été faites également dans les pilotes FAT et EXFAT.
Correction des requêtes sur l’attribut « dernière modification », et amélioration de la gestion du type « time » pour éviter les conversions inutiles (ce type d’attribut est historiquement stocké en 32 bits mais migré en 64 bits lorsque c’est possible pour éviter le bug de l’an 2038, aussi le code doit être capable de traiter ces 2 formats de stockage).
packagefsLe système de fichier packagefs est au centre de la gestion des paquets logiciels dans Haiku. Les paquets ne sont pas extraits sur le disque, mais montés dans un système de fichier spécifique (qui implémente une version tout-en-un de ce qui pourrait être réalisé sous Linux avec squashfs et overlayfs).
Ce système de fichier se trouve donc sur le chemin critique en termes de performances, ce qui fait que même de petites optimisations peuvent déboucher sur de gros gains de performance.
Optimisation de la gestion de la mémoire: utilisation d’un allocateur dédié pour allouer et désallouer très rapidement de la mémoire de travail avec une durée de vie courte.
Ajout d’une vérification manquante sur la présence du dossier parent, qui pouvait déclencher un kernel panic.
NFS4Le pilote NFS4 permet de monter des partages réseau NFS. Cependant, le pilote ne fonctionne pas toujours, et certains utilisateurs doivent se rabattre sur le pilote NFS v2 (ancienne version du protocole de moins en moins utilisée), ou encore sur des systèmes de fichiers FUSE comme SMB ou sshfs.
Le pilote NFS4 peut maintenant être compilé avec userlandfs (équivalent de FUSE pour Haiku) pour s’exécuter en espace utilisateur. Cela facilitera le déboguage.
ramfs et ram_diskram_disk est un périphérique de stockage qui stocke les données en RAM, il a une taille fixe et doit être formaté avec un système de fichiers avant de pouvoir être utilisé.
ramfs est un système de fichier stockant les données directement en RAM sans passer par un périphérique de stockage de type bloc. Sa taille est dynamique en fonction des fichiers qui sont stockés dedans.
Ces deux pilotes ont reçu divers nettoyages et corrections, suite à des problèmes mis en évidence par des assertions ajoutées précédemment dans le code.
Dans le ramfs, nettoyage de code dupliqué, réduction de la contention sur les verrous, amélioration de la fonction readdir pour retourner plusieurs entrées d’un coup au lieu de les égréner une par une.
Ajout de la gestion des fichiers « spéciaux » (FIFOs nommés, sockets UNIX) dans ramfs.
AutresRefonte de l’algorithme de « scoring » des requêtes sur les systèmes de fichiers. Cet algorithme permet d’estimer quels sont les termes de la requête les moins coûteux à évaluer, afin de réduire rapidement le nombre de fichiers répondant aux critères, et d’effectuer les opérations complexes seulement sur un petit nombre de fichiers restants. Les requêtes s’exécutent ainsi encore plus rapidement (waddlesplash).
Réécriture du code pour identifier les partitions dans mount_server. Ce code permet de re-monter les mêmes partitions après un redémarrage de la machine, mais l’ancien algorithme pouvait trouver de faux positifs et monter des partitions supplémentaires (OscarL et waddlesplash).
Correction d’une option de debug pour intercepter les accès aux adresses non initialisées (0xcccccccc) ou déjà libérées (0xdeadbeef). Cela permet de détecter certains accès à des pointeurs invalides. Cette option ne fonctionnait correctement que sur les systèmes 32 bit, maintenant, l’adresse correspondante pour les machines 64 bit est également protégée.
librootLa libroot est la librairie C de base de Haiku. Elle regroupe les fonctions parfois implémentées dans les libc, libm, libpthread, librt et libdl pour d’autres systèmes. Haiku choisit une approche tout-en-un, car il est excessivement rare qu’une application n’ait pas besoin de toutes ces bibliothèques.
Du fait de la grande diversité des services rendus par cette bibliothèque, il est difficile de présenter les changements de façon cohérente et organisée.
Correction de quelques cas particuliers dans le traitement des tableaux de descripteurs de fichiers pour select() et déplacement d’une partie des définitions de sys/select.h vers des en-têtes privés non exposés aux applications (waddlesplash).
Ajout d’une fonction manquante dans les « stubs » de la libroot, qui sont utilisés lors de la compilation de Haiku en mode « bootstrap » (sans aucune dépendance précompilée externe). Les stubs sont normalement générés à l’aide d’un script, mais celui-ci n’avait pas pris en compte une fonction nécessaire seulement sur les architectures x86.
Poursuite du travail d’unification des fonctions de manipulation des temps d’attentes pour toutes les fonctions de la libroot qui peuvent déclencher un timeout. Correction d’un cas où la fonction pthread_testcancel retournait NULL au lieu de la valeur attendue PTHREAD_CANCELED.
Optimisation de la fonction strcmp, remplacement d’autres fonctions avec de meilleures implémentations provenant de la bibliothèque C musl.
Compatibilité POSIX-2024La spécification POSIX Issue 8 a été publiée et comporte de nombreux changements. Après la version 7, la façon de travailler est devenue plus ouverte, avec un outil de suivi de bugs permettant de proposer des améliorations. Cela conduit à la standardisation de nombreuses extensions qui sont communes entre les systèmes GNU et BSD, rendant plus facile d’écrire du code portable entre tous les systèmes compatibles POSIX.
- Ajout de fonctions qui ouvrent des descripteurs de fichiers avec le drapeau O_CLOEXEC activé par défaut (dup2, pipe3)
- Ajout de reallocarray (un mélange de calloc et realloc)
- Ajout de memmem (recherche d’une suite d’octets dans une zone de mémoire)
- Ajout de mkostemp
- Ajout de posix_devctl et modifications de l’implémentation de ioctl
- Ajout de pthread_getcpuclockid pour mesurer le temps CPU consommé par un thread
- Ajout de la constante d’erreur ESOCKTNOSUPPORT bien qu’elle ne soit jamais utilisée (cela facilite le portage d’applications qui attendent l’existence de ce code d’erreur)
- Correction d’une boucle infinie dans pipe2
- Suppression des fonctions *randr48_r des en-têtes publics. Il s’agit d’une extension disponible uniquement dans la glibc, et qui ne devrait donc pas être disponible dans la libroot. Cependant, l’implémentation est conservée pour assurer la compatibilité d’ABI avec les applications existantes.
La fonction ioctl existe depuis le début de UNIX et permet de réaliser des opérations spéciales sur les descripteurs de fichiers (tout ce qui n’est pas une simple lecture ou écriture). En particulier, elle est beaucoup utilisée pour les pilotes de périphériques qui exposent une interface sous forme de fichiers dans /dev.
L’existence de cette fonction était demandée dans la spécification POSIX, mais son fonctionnement n’était pas documenté à l’exception de quelques cas particuliers. La documentation spécifie une fonction avec un nombre d’arguments variable : un numéro de descripteur de fichier, un identifiant de l’opération à effectuer, puis des paramètres qui dépendent de l’opération. On trouve des opérations avec aucun, un, ou deux paramètres.
Dans UNIX et la plupart de ses dérivés, la liste des opérations possibles est définie à l’avance, et le format des numéros identifiants permet de déterminer de façon prédictible quel est le nombre de paramètres attendus. Ce n’est pas le cas dans Haiku : les pilotes de périphériques ont le choix d’assigner n’importe quelle valeur à n’importe quelle opération, et la même valeur numérique peut donc avoir une signification différente selon le type de fichier.
L’opération ioctl est donc en réalité implémentée avec toujours 4 arguments pour Haiku : en plus des deux déjà mentionnés, il faut ajouter un pointeur vers une zone de mémoire, et un entier indiquant la taille de cette zone. Des acrobaties à base de macros permettent de remplir ces deux paramètres avec des valeurs par défaut lorsqu’ils ne sont pas nécessaires (au moins pour les programmes écrits en C ; en C++, ces deux paramètres sont simplement déclarés avec une valeur par défaut).
Heureusement, ces problèmes avec ioctl vont être résolus, puisque POSIX a introduit une nouvelle fonction en remplacement : posix_devctl. Celle-ci fonctionne comme l’implémentation de ioctl dans Haiku, mais les arguments doivent toujours être spécifiés explicitement. Cela va donc permettre de disposer d’une interface réellement portable pour ces opérations.
KernelCorrection de la taille du tampon mémoire par défaut de la classe KPath qui permet au noyau de manipuler des chemins dans le système de fichiers (waddlesplash).
VFSLe VFS (virtual filesystem) est l’interface entre les appels systèmes d’accès aux fichiers (open, read, write…) et les systèmes de fichiers proprement dit. En plus de ce travail d’interfaçage (par exemple : convertir un chemin de fichier absolu en chemin relatif à un point de montage), cette couche regroupe un ensemble de fonctionnalités qui n’ont pas besoin d’être réimplémentées par chaque système de fichier: vérification des permissions, mémoire cache pour limiter les accès au disque.
Si les systèmes de fichiers identifient chaque objet par un inode (en général lié à la position de l’objet sur le disque ou dans la partition de stockage), le VFS travaille lui avec des vnode qui existent uniquement en RAM et sont alloués dynamiquement pour les fichiers en cours d’utilisation.
D’autre part, les systèmes de fichiers peuvent se reposer sur un cache de blocs. Ce dernier se trouve plutôt à l’interface entre un système de fichier et le support de stockage correspondant, puisqu’il fonctionne au niveau des blocs de données stockées sur disque. Mais son intégration avec le VFS est nécessaire pour savoir quels sont les fichiers en cours d’utilisation et les opérations prévisibles sur chacun (par exemple, il est utile de pré-charger la suite d’un fichier lorsque un programme demande à en lire le début, car il est probable que ces informations vont bientôt être nécessaires).
Le VFS est donc un élément central en particulier pour obtenir de bonnes performances sur les accès aux fichiers, en minimisant les accès aux vrais systèmes de fichiers qui doivent maintenir beaucoup d’informations à jour sur les disques. Tout ce qui peut être traité en utilisant uniquement la RAM grâce à la mise en cache est beaucoup plus rapide.
Investigation et amélioration des performances de la commande git status qui prenait beaucoup plus de temps à s’exécuter que sur d’autres systèmes (waddlesplash):
- Meilleure gestion des vnodes inutilisés à l’aide d’une liste chaînée 'inline' protégée par un spinlock, à la place d’un mutex peu performant dans ce code très fréquemment appelé.
- Modification de la structure io_context pour utiliser un verrou en lecture-écriture (permettant plusieurs accès concurrents en lecture, mais un seul en modification).
- Ajout d’un chemin rapide dans le cas le plus simple de la recherche de vnode.
Avec ces changements, les performances sont améliorées au moins lorsque les données nécessaires sont déjà disponibles dans le cache disque.
Nettoyage et corrections dans les fonctions d’entrées-sorties vectorisées et asynchrones do_iterative_fd_io et do_fd_io utilisées par les systèmes de fichiers: meilleure gestion des références et prise en compte de certains cas particuliers. Cela permet de simplifier un peu le code de pré-remplissage du cache de blocs (waddlesplash).
La prise en compte des drapeaux O_RDONLY|O_TRUNC lors de l’ouverture d’un fichier est maintenant faite directement dans le VFS, il n’est plus nécessaire de transmettre la requête au système de fichier. Cette combinaison de drapeaux est un comportement indéfini dans POSIX, et supprime le contenu du fichier dans Linux. Dans Haiku, elle remonte une erreur.
Correction du comportement de l’ouverture d’un symlink invalide (ne pointant pas sur un fichier) avec le flag O_CREAT.
Le parser de requêtes pouvait essayer de lire des données invalides (la taille de clé d’un index inexistant) dans certains cas particuliers.
Nettoyage de logs dans tous les systèmes de fichiers qui affichaient un message lors de chaque tentative d’identification. On avait donc un message de chaque système de fichier pour chaque partition. Maintenant, le cas le plus courant (le système de fichier ne reconnaît pas du tout la partition) ne déclenche plus de logs.
Correction d’une erreur dans userlandfs sur la fonction file_cache_read pour les tentatives d’accès après la fin d’un fichier (cas particulier nécessaire pour implémenter correctement mmap).
Correction d’une mauvaise gestion du errno dans le cache de blocs, qui pouvait aboutir à un kernel panic.
Diverses améliorations, nettoyages et corrections de fuites mémoire: dans la gestion des fichiers montés comme image disques, dans les entrées-sorties asynchrones, dans l’enregistreur d’évènements scheduling recorder.
Console et affichageUnification du code d’affichage du splash screen (par le bootloader) et des icônes de la séquence de démarrage (par le kernel) pour éviter qu’ils prennent des décisions différentes sur le positionnement (par exemple si l’un est compilé pour afficher le logo de Haiku, et l’autre en version « dégriffée » sans ce logo qui est une marque déposée) (waddlesplash).
Initialisation de la console framebuffer beaucoup plus tôt dans le démarrage du noyau, ce qui permet d’afficher un message à l’écran en cas de kernel panic y compris dans les premières étapes du démarrage (par exemple, l’initialisation de la mémoire virtuelle). Auparavant, ces informations étaient disponibles uniquement dans le syslog (inaccessible si le système ne démarre pas) ou via un port série (en voie de disparition sur les machines modernes) (waddlesplash).
RéseauRemontée des données annexes (ancillary data) en une seule fois lorsque c’est possible. Ces données sont utilisées en particulier dans les sockets de domaine AF_UNIX pour permettre d’échanger des descripteurs de fichiers entre processus. Ce regroupement de données n’est pas exigé par la spécification POSIX, mais c’est le comportement attendu par le code de communication interprocessus de Firefox et de Chromium (ils utilisent tous les deux le même code) (waddlesplash).
Gestion de la mémoireComme indiqué plus haut dans la dépêche, l’apparition du navigateur Iceweasel a mis en évidence de nombreux problèmes autour de la gestion de la mémoire. Cela a donc été l’objet d’un gros travail de stabilisation et d’amélioration.
- Le cache d’objets du noyau pouvait parfois ignorer le paramètre indiquant la réserve minimum d’objets devant toujours être disponibles (waddlesplash)
- Amélioration de l’implémentation de la famille de fonctions autour de mprotect, qui permettent une gestion fine et bas niveau de la mémoire. En particulier, plusieurs problèmes se posaient lors de l’utilisation de ces fonctions lors d’un appel à fork, les deux processus se retrouvant dans un état incohérent,
- Suppression de logs présents dans les méthodes de défaut de page, qui sont peu appelées pour les applications classiques, mais exploitées volontairement par d’autres applications (machines virtuelles Java ou Javascript par exemple). Les logs étaient donc superflus dans ce cas (waddlesplash),
- Optimisation de l’écriture par lot de plusieurs pages de mémoire vers le swap,
- Meilleure gestion des permissions d’accès page par page,
- Correction de plusieurs problèmes conduisant à un blocage ou fort ralentissement du système quand il n’y a plus assez de mémoire libre,
- Amélioration de la stratégie d’allocation de la table des descripteurs de fichiers,
- Regroupement de code dupliqué pour chaque plateforme qui était en fait générique.
Ce travail se poursuit avec un remplacement de l’allocateur mémoire actuel, qui est basé sur hoard2. Cette implémentation est assez ancienne et montre aujourd’hui ses limites. Des essais sont en cours avec l’implémentation de malloc d’OpenBSD, ainsi qu’avec mimalloc de Microsoft, pour déterminer lequel des deux sera utilisé. D’autres allocateurs ont été rejetés, car ils ne répondent pas au besoin de Haiku, en particulier la possibilité de fonctionner efficacement sur un système 32 bits ou l’espace d’adressage est une ressource limitée.
AutresSécurisation des permissions sur les zones mémoire partagées: une application ne peut pas ajouter des permissions en écriture aux zones mémoire d’une autre application. Une application qui n’est pas lancée par l’utilisateur root ne peut pas inspecter la mémoire d’une application lancée par l’utilisateur root. Ajout toutefois de cas particuliers pour permettre au Debugger de faire son travail (il a besoin d’accéder à la mémoire d’autres applications).
Ajout et amélioration de commandes dans le debugger noyau pour investiguer l’état de l’ordonnanceur d’entrées-sorties, qui se charge de programmer les accès disque dans un ordre le plus efficace possible (waddlesplash).
La fonction vfork n’appelle plus les fonctions pre-fork. Haiku n’implémente pas complètement vfork, mais peut se permettre des optimisations sur le travail qu’un duo fork + exec classique demanderait normalement.
La configuration de la randomization de l’espace mémoire (ASLR) est maintenant faite par la libroot et pas par le noyau. Ainsi une application peut utiliser une version différente de la libroot pour avoir une politique de randomization différente.
Optimisation de l’accès par un thread à sa propre structure Thread
Chargeur de démarrageL’écran de démarrage s’affiche correctement sur les systèmes EFI utilisant un mode écran avec une profondeur de couleur 16 bits (korli).
Affichage de la taille des partitions démarrables dans le menu de démarrage, pour faciliter leur identification (waddlesplash).
Activation des warnings du compilateur sur les chaînes printf invalides.
Augmentation de la zone de mémoire utilisée pour la décompression de l’archive de démarrage lors du boot sur le réseau, l’archive était devenue trop grosse suite à l’ajout de nouveaux pilotes.
Refactorisation du code de gestion de la mémoire entre le bootloader et le runtime_loader, ajout de tests pour cette implémentation, et optimisation de l’utilisation mémoire du bootloader.
Amélioration du comportement si le device tree définit un port série sans spécifier de baudrate: le bootloader suppose que le baudrate est déjà configuré, et utilise le port sans essayer de le réinitialiser.
Outils de compilationLa compilation de Haiku est un processus relativement complexe: il faut utiliser deux compilateurs pour Haiku lui-même (un gcc récent plus une version plus ancienne pour assurer la compatibilité avec BeOS) ainsi que un compilateur pour le systême hôte de la compilation (qui peut être Linux, BSD, Mac OS ou Windows) pour générer des outils nécessaires à la compilation elle-même. L’outil retenu est Jam, une alternative à Make avec une meilleure gestion des règles génériques réutilisables.
- Ajout de vérification pour éviter d’avoir un build partiellement configuré, avec des ConfigVars définies mais vides.
- Retrait d’un warning incorrect dans l’outil de build jam si on spécifie à la fois un profil et une cible de compilation sur la ligne de commande.
- Reconnaissance des processeurs hôtes ARM et RISC-V pour la compilation croisée, correction d’autres problèmes avec les architectures non-x86.
- Ajout de dépendances manquantes dans les règles de compilation de packagefs.
- Suppression de fichiers de licence fournis avec Haiku mais concernant du code qui avait été supprimé de Haiku auparavant.
- Amélioration de la remontée d’erreur du script configure si un interpréteur Python n’a pas été trouvé.
- Correction de messages d’avertissement de awk pour l’utilisation de fonctions qui n’existent plus dans le traitement des fichiers d’identifiants matériels USB et PCI.
Ajout de documentation sur les détails d’implémentation de ioctl et posix_devctl et les spécificités de Haiku pour la première (PulkoMandy).
Correction de fautes de frappe dans l’introduction au launch_daemon.
Remplacement de toutes les références à "OpenBeOS" par "Haiku".
Documentation d’APIAjout de documentation pour les méthodes GetFontAndColor et SetFontAndColor de BTextView.
Ajout de documentation pour les classes BShelf et BGameSound.
Réorganisation de la liste des caractères de contrôles dans la documentation du clavier, ajout d’entrées manquantes dans cette liste et ajoute de commentaires indiquant à quelles combinaisons de touches ces caractères sont normalement associés.
Traductions de HaikuLa traduction du système dans différentes langues est un facteur important d’inclusivité et d’accessibilité (même si la communication avec l’équipe de développeurs pour le support n’est pas toujours simple).
Haiku est disponible dans 30 langues, la trentième étant le coréen, pour lequel il y a un nouveau responsable des traductions (le précédent avait cessé toute activité et laissé la traduction inachevée).
Haiku recherche des volontaires pour s’occuper des traductions en biélorusse, croate, bulgare, hindi, punjabi et slovène, pour lesquelles les précédents responsables de relectures n’ont plus le temps d’assurer le rôle. Ainsi bien sûr que de l’aide pour la traduction du système, du manuel d’utilisation, et des applications tierces, que ce soit pour ajouter de nouvelles langues ou pour renforcer les équipes s’occupant de langues existantes. Le point d’entrée est le portail d’internationalisation de Haiku.
La traduction du système Haiku s’effectue avec Pootle. L’outil n’est plus développé et des investigations sont en cours pour le remplacer par Weblate. La traduction du manuel d’utilisation s’effectue avec [un outil spécifiquement développé pour cela](https://github.com/haiku/userguide-translator. La traduction des applications s’effectue également avec un outil personnalisé nommé Polyglot.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Yvonne Choquet-Bruhat, les ondes gravitationnelles et Einstein
Yvonne Choquet-Bruhat (1923 - 2025) vient de s’éteindre à l’âge de 101 ans. Ses travaux sur les ondes gravitationnelles sont d’une importance majeure et lui ont valu une reconnaissance internationale. Médaillée d’argent du CNRS, elle était récipiendaire des prix Dannie-Heineman de la Société américaine de physique et Marcel Grossmann. Elle était membre de l’Académie des sciences de Paris et l’une des rares scientifiques à avoir été décorée de la Légion d’Honneur au grade de grand-croix (2016), le plus élevé. Elle était aussi grand-croix de l’ordre national du Mérite depuis 2015.
Parcours d’une grande scientifique.
- lien nᵒ 1 : « Einstein m’a félicitée » : décès d'Yvonne Choquet-Bruhat
- lien nᵒ 2 : Editorial note to: Existence theorem for the Einsteinian gravitational field equations...
- lien nᵒ 3 : Yvonne Choquet-Bruhat, première femme médaillée d’argent au CNRS
- lien nᵒ 4 : Publications d’Yvonne Choquet-Bruhat
- Une famille d’universitaires
- La rencontre avec Einstein
- Une carrière couverte d’honneurs et de publications
- De l’importance de son travail
- Au besoin, ces quelques liens
Yvonne Bruhat est issue d’une famille d’universitaires. Sa mère, Berthe Hubert, est professeur agrégée de philosophie, son père, Georges Bruhat, est physicien, il enseigne à l’École normale supérieure et la Faculté des sciences de Paris. Il est, notamment l’auteur, de 1924 à 1934, d’un Cours de physique générale en quatre tomes qui connaîtra plusieurs rééditions jusque dans les années 1960. Son frère, François Bruhat sera aussi un éminent mathématicien.
Georges Bruhat est déporté en 1944 pour avoir refusé de donner à la Gestapo les coordonnées d’un de ses élèves résistant. Bruhat meurt le 31 décembre 1944 ou le 1er janvier 1945 au camp de concentration d’Oranienbourg-Sachsenhausen. L’arrestation de son père par la Gestapo ne sera pas sans incidence sur les relations d’Yvonne avec Einstein.
La rencontre avec EinsteinYvonne Bruhat est reçue au concours de l’École normale supérieure de Sèvres (ENS) en 1943. Elle suit les cours de mathématiques de Georges Darmois, Jean Leray qui la présentera à Einstein et André Lichnerowicz qui sera son directeur de thèse. Entrée première à l’ENS, elle sera aussi première à l’agrégation de mathématiques en 1946. Elle devient professeure assistante à l’ENS, épouse Léonce Fourès dont elle divorcera ensuite. Elle commence à acquérir, notamment sur le plan international, une réputation, sous le nom Fourès-Bruhat. Elle se fait connaître en 1950 avec un article : Théorème d’existence pour les équations de la gravitation einsteinienne dans le cas non analytique présenté à l’Académie des sciences de Paris par Jacques Hadamard, considéré comme le mathématicien le plus important de son temps. Elle avait auparavant signé d’autres articles seule ou avec André Lichnerowicz.
Elle soutient sa thèse en 1950 : Théorème d’existence pour certains systèmes d’équations aux dérivées partielles non linéaires. À la suite de cela, elle sera invitée à venir faire des études post-doctorales à l’Institute for Advanced Study de Princeton de 1951 à 1952 où Albert Einstein et Jean Leray travaillaient. Ce dernier, dont elle était l’assistante de cours, la présente à Einstein :
précisant que j’avais fait une thèse sur « sa » relativité générale et que j’étais la fille de Georges Bruhat.
À partir de ce moment, j’ai eu l’entière sympathie d’Einstein qui était sensible à tous ceux qui s’étaient opposés au nazisme. Il m’a invitée alors dans son bureau me demandant de lui expliquer ma thèse au tableau. Mon anglais n’était pas fameux malgré mes dix années d’étude de la langue de Shakespeare… Il m’a dit de l’expliquer en français, langue qu’il comprenait, mais qu’il me répondrait en anglais… (Yvonne Choquet-Bruhat, interview Science et Avenir, 13 février 2025).
Elle ira le voir assez souvent pendant son séjour à Princeton.
Une carrière couverte d’honneurs et de publicationsRentrée en France, elle rejoint son poste de maîtresse de conférence à l’Université de Marseille. Elle repart à Princeton pour une année en 1955-1956, pour ensuite aller enseigner à Reims. Elle devient professeure à la faculté des sciences de Paris, poste qu’elle occupe de 1960 à 1970, puis elle rejoint l’université Pierre-et-Marie-Curie où elle enseigne jusqu’à sa retraite en 1992.
Elle reçoit de nombreuses distinctions, à commencer par la médaille d’argent du CNRS en 1958, une médaille créée en 1954 qui « distingue des chercheurs et des chercheuses pour l’originalité, la qualité et l’importance de leurs travaux, reconnus sur le plan national et international » (CNRS)1.
En 1963, elle est récipiendaire du prix Henri de Parville de l’Académie des sciences de Paris. Elle y sera élue en 1973, trois ans après son époux le mathématicien Gustave Choquet2. Une académie qui a dû trouver drôle d’avoir une femme en son sein, la première depuis sa création en 1666, et dont son fils, Daniel Choquet est membre depuis 2004.
Elle est, de 1980 à 1983, présidente de l’International Society on General Relativity and Gravitation (ISGRG), une société savante dont l’objectif est de promouvoir la recherche sur la relativité générale et la gravitation.
1985 est l’année où elle est élue à l’Académie américaine des arts et sciences, une société dont l’objectif est de « cultiver chacun des arts et des sciences qui peuvent contribuer à faire avancer l’intérêt, l’honneur, la dignité et le bonheur d’un peuple libre, indépendant et vertueux ».
En 2003, elle reçoit le prix Dannie-Heineman de physique mathématique, conjointement avec le physicien américain James W. York qui a travaillé avec elle sur l’équation de champ d’Einstein. Ce prix est décerné chaque année par la Société américaine de physique et l’American Institute of Physics pour récompenser un travail remarquable en physique mathématique. L’année suivante, toujours avec James W. York, elle est récipiendaire du prix Daniel Grossman, décerné par l’ICRA (International Center for Relativistic Astrophysics, un institut de recherche italien) pour leur travail séparément ou ensemble « dans l’établissement du cadre mathématique pour prouver l’existence et l’unicité des solutions aux équations de champ gravitationnelles d’Einstein ».
Elle devient grand-croix de l’ordre national du Mérite en 2015 et de la Légion d’honneur en 2016.
En 2023, une journée spéciale est organisée en son honneur par le CNRS, le 8 décembre. Le physicien Thibault Damour de l’Institut des Hautes Études Scientifiques (IHES) y délivre une conférence d’une heure (dans un anglais peu compréhensible) sur les recherches d’Yvonne Choquet-Bruhat.
Ses publications s’étalent dans le temps de 1948, « Sur une expression intrinsèque du théorème de Gauss en relativité générale » Comptes-rendus hebdomasaires des séances de l’Académie des Sciences de Paris, volume 226, pages 218–220, à 2016.
Ses deux derniers livres scientifiques « General Relativity and the Einstein Equations », Oxford Mathematical Monographs. Oxford University Press (Oxford, UK), 2009 et « Introduction to General Relativity, Black Holes & Cosmology », Oxford University Press (Oxford, UK), 2015. Elle a également écrit ses mémoires en 2016 : Une mathématicienne dans cet étrange univers : mémoires. Odile Jacob (Paris). Lesquels ont été traduits en anglais en 2018.
Son article « Théorème d’existence pour les équations de la gravitation einsteinienne dans le cas non analytique » paru en 1950 dans les Comptes-rendus hebdomadaires des séances de l’Académie des sciences de Paris a été republié en 2022.
De l’importance de son travailL’astrophysicienne Françoise Combes, présidente de l’Académie des sciences de Paris évoque dans un hommage à Yvonne Choquet-Bruhat son apport aux sciences mathématiques et physiques. Son apport essentiel a été la démonstration de l’existence des solutions à l’équation d’Albert Einstein dans la relativité générale, quelque chose de très complexe. Elle avait prédit les ondes gravitationnelles qui n’ont été détectées qu’en 2015. Albert Einstein avait aussi prédit ces ondes gravitationnelles mais sans trop y croire, car il était impossible de les détecter compte-tenu de leur taille :
pour observer le signal produit par la fusion de deux trous noirs de quelques masses solaires, il faut pouvoir mesurer des vibrations de l’espace correspondant à des variations de longueur 10 000 fois plus petites que la taille d’un proton ! (CNRS, le journal, Mathieu Grousson, 12 février 2024).
Une observation rendue possible grâce aux équations d’Yvonne Choquet-Bruhat et à l’augmentation de la sensibilité des détecteurs.
Une mesure de l’importance de son travail pourrait être appréhendée, outre par les résultats concrets de la découverte des ondes gravitationnelles et les honneurs qui lui sont rendus post-mortem, en examinant « le sort » fait à ses publications. À peu près tous ses articles ont fait l’objet d’une traduction en anglais. Et, si on examine ses publications sur la plateforme inspirehep.net qui se revendique comme une « communauté de confiance qui aide les chercheurs à partager et à trouver des informations scientifiques précises dans le domaine de la physique des hautes énergies. », on voit qu’une de ses publications est assez citée : « Global aspects of the Cauchy problem in general relativity », co-écrite par Yvonne Choquet-Bruhat et Robert Geroch en 1969 qui a été citée 334 fois depuis sa parution dont 121 de 2020 à 2024 inclus.
Au besoin, ces quelques liensL’annonce du décès d’Yvonne Choquet-Bruhat a fait l’objet d’un nombre assez important d’articles de qualité assez inégales. Côté francophone, on insiste beaucoup sur le fait qu’elle a été la première femme admise à l’Académie des sciences. Ce qui est assez agaçant parce qu’elle y a été admise pour ses travaux qui passent un peu à la trappe de fait. Cette sitographie est donnée sans ordre particulier. Les articles mis dans les « Liens » sont, à mon avis, vraiment les plus intéressants aussi parce qu’il s’agit d’entretiens avec la mathématicienne.
- Mort d’Yvonne Choquet-Burhat, la scientifique qui a émerveillé Einstein, un article en catalan du journal catalan El Punt Avui+ (cat). Son auteur, Lluís Simon considère que l’Europe a perdu, avec la disparition d’Yvonne Choquet-Bruhat, une des plus influentes mathématiciennes et physiciennes.
- Elle discutait avec Einstein à Princeton, la mathématicienne Yvonne Choquet-Bruhat vient de décéder à 101 ans !, Futura-sciences.
- Mort d’Yvonne Choquet-Bruhat, la première femme élue à l’Académie des sciences, Anna Musso, L’Humanité, 13 février 2022.
- La mort d’Yvonne Choquet-Bruhat, pionnière des études sur les ondes gravitationnelles, David Larousserie, 12 février 2025.
- Yvonne Choquet-Bruhat, les médailles d’argent du CNRS (et Wikif).
- Disparition d’Yvonne Choquet-Bruhat, Institut de France, c’est très court.
- Décès d’Yvonne Choquet-Bruhat, une pionnière des mathématiques et de la physique, Académie des sciences, il y a une courte vidéo ou Françoise Combes rend hommage à Yvonne Choquet-Bruhat, 12 février 2025.
- Page Wikipédia.
- Yvonne Choquet-Bruhat (1923-2025), IHES, 11 février 2025.
- Disparition d'Yvonne Choquet-Bruhat, scientifique et pionnière, Terrienne, Liliane Charrier, TV5Monde, 13 février 2025.
Le compte-rendu des séances hebdomadaires de l’Académie des sciences de janvier à juin 1950 peut être téléchargé au format PDF uniquement (texte-image) sur Gallica-BnF. La séance qui nous intéresse est pages 620-624 du PDF, 618-622 pour la publication. Le PDF a 2492 pages et pèse 136 Mio. On devrait pouvoir retrouver celui d’autres séances passées.
Si les ondes gravitationnelles vous intéressent, le CNRS y a consacré un dossier.
-
À noter, l’équipe de Wikif (Wikipédia et les femmes de science) a relevé la liste des noms des titulaires des médailles du CNRS. Dans le dossier N°20130496, on voit en face du nom d’Yvonne Bruhat : médaille de bronze 1955 / médaille d’argent 1956. ↩
-
Fait intéressant : il semble que l’encyclopédie Universalis, à laquelle on peut accéder avec un pass BnF lecture/culture ait une notice sur Gustave Choquet, mais pas sur Yvonne Choquet-Bruhat. C’est d’autant plus intéressant quand on compare avec Wikipédia où la page de cette dernière est traduite en vingt-et-une langues, quand celle de son époux ne l’est qu’en neuf langues. ↩
Commentaires : voir le flux Atom ouvrir dans le navigateur
Agenda du Libre pour la semaine 8 de l’année 2025
Calendrier Web, regroupant des événements liés au Libre (logiciel, salon, atelier, install party, conférence), annoncés par leurs organisateurs. Voici un récapitulatif de la semaine à venir. Le détail de chacun de ces 37 événements (France: 36, internet: 1) est en seconde partie de dépêche.
- lien nᵒ 1 : April
- lien nᵒ 2 : Agenda du Libre
- lien nᵒ 3 : Carte des événements
- lien nᵒ 4 : Proposer un événement
- lien nᵒ 5 : Annuaire des organisations
- lien nᵒ 6 : Agenda de la semaine précédente
- lien nᵒ 7 : Agenda du Libre Québec
-
- [FR Montpellier] Émission | Radio FM-Plus | Temps Libre | Diffusion – Le lundi 17 février 2025 de 09h00 à 10h00.
- [FR Annecy-le-Vieux] #OSM Rencontre mensuelle du groupe OpenStreetMap Annecy – Le lundi 17 février 2025 de 18h45 à 21h00.
- [FR Montpellier] Atel'libre | Groupia – Le lundi 17 février 2025 de 19h00 à 21h00.
- [internet] Émission «Libre à vous!» – Le mardi 18 février 2025 de 15h30 à 17h00.
- [FR Vandœuvre-lès-Nancy] Sciences participatives – Le mardi 18 février 2025 de 18h00 à 20h30.
- [FR Lyon] OpenStreetMap, rencontre mensuelle – Le mardi 18 février 2025 de 18h30 à 20h00.
- [FR Vergèze] Atelier FreeCAD – Le mardi 18 février 2025 de 18h30 à 21h30.
- [FR Grenoble] Install Party + Rencontre FairPhone – Le mardi 18 février 2025 de 19h00 à 21h00.
- [FR Le Mans] Permanence du mercredi – Le mercredi 19 février 2025 de 12h30 à 17h00.
- [FR Mauguio] GNU/Linux et Logiciels Libres – Le mercredi 19 février 2025 de 17h00 à 19h00.
- [FR Pessac] Cours gratuit d’Espéranto, langue Libre – Le mercredi 19 février 2025 de 17h30 à 19h00.
- [FR Beauvais] Sensibilisation et partage autour du Libre – Le mercredi 19 février 2025 de 18h00 à 20h00.
- [FR Bordeaux] Libérez-vous : La monnaie Libre G1 / June – Le mercredi 19 février 2025 de 19h45 à 22h00.
- [FR Echirolles] AlpOSS – Le jeudi 20 février 2025 de 09h00 à 20h00.
- [FR Joué-lès-Tours] Atelier du Libre – Le jeudi 20 février 2025 de 13h30 à 16h00.
- [FR Chambery] Contribution au Libre – Contributions à l’association – Le jeudi 20 février 2025 de 18h00 à 22h00.
- [FR Bordeaux] Découverte de l’Espéranto – Le jeudi 20 février 2025 de 18h00 à 19h30.
- [FR Villeurbanne] Découvrir Openstreetmap : La Carte Libre dont vous êtes les héros – Le jeudi 20 février 2025 de 18h30 à 20h00.
- [FR Montpellier] Aprilapéro – Le jeudi 20 février 2025 de 19h00 à 21h00.
- [FR Montpellier] L’apéro des quatre libertés – Le jeudi 20 février 2025 de 19h00 à 21h00.
- [FR Montpellier] FSFapéro – Le jeudi 20 février 2025 de 19h40 à 20h20.
- [FR Montpellier] Quadrapéro – Le jeudi 20 février 2025 de 20h20 à 21h00.
- [FR Dunkerque] Logiciels Libres : introduction, aux Glacis – Le vendredi 21 février 2025 de 14h00 à 16h00.
- [FR Paris] Guix@Paris – Le vendredi 21 février 2025 de 19h00 à 22h00.
- [FR Annecy] Réunion hebdomadaire AGU3L Logiciels Libres – Le vendredi 21 février 2025 de 20h00 à 23h59.
- [FR Metz] Permanence du Graoulug – Le samedi 22 février 2025 de 09h00 à 13h00.
- [FR Marignier] Utilisation d’internet – Le samedi 22 février 2025 de 09h00 à 12h00.
- [FR Aix-en-Provence] Réunion mensuelle de l’Axul – Le samedi 22 février 2025 de 10h00 à 16h00.
- [FR Ivry sur Seine] Cours de l’École du Logiciel Libre – Le samedi 22 février 2025 de 10h30 à 18h30.
- [FR Wintzenheim] Réunion du Club Linux – Le samedi 22 février 2025 de 13h00 à 19h00.
- [FR Digne-les-Bains] Rencontre Logiciels libres – Le samedi 22 février 2025 de 13h30 à 17h00.
- [FR Marseille] Install Party GNU/Linux – Le samedi 22 février 2025 de 14h00 à 18h00.
- [FR Saint-Cyr-l’École] Permanences logiciels libres – pc et smartphones – Le samedi 22 février 2025 de 14h00 à 17h00.
- [FR Nant] Conférences et projection/débat Journée sur les enjeux sociétaux et environnementaux du numérique – Le samedi 22 février 2025 de 14h00 à 21h00.
- [FR Nantes] Permanence Linux-Nantes – Le samedi 22 février 2025 de 15h00 à 18h00.
- [FR Faches-Thumesnil] Install Party GNU Linux – Le samedi 22 février 2025 de 15h00 à 18h00.
- [FR Quimper] Permanence Linux Quimper – Le samedi 22 février 2025 de 16h00 à 18h00.
Montpel'libre réalise une série d’émissions régulières à la Radio FM-Plus intitulées « Temps Libre ». Ces émissions sont la présentation hebdomadaire des activités de Montpel’libre.
Après le jingle où l’on présente brièvement Montpel'libre, nous donnerons un coup de projecteur sur les activités qui seront proposées prochainement.
Ces émissions seront l’occasion pour les auditeurs de découvrir plus en détails les logiciels libres et de se tenir informés des dernières actualités sur le sujet.
Alors, que vous soyez débutant ou expert en informatique, que vous ayez des connaissances avancées du logiciel libre ou que vous souhaitiez simplement en savoir plus, Montpel'libre, au travers de cette émission, se fera un plaisir pour répondre à vos attentes et vous accompagner dans votre découverte des logiciels libres, de la culture libre et des communs numériques.
Vous vous demandez peut-être ce qu’est un logiciel libre. Il s’agit simplement d’un logiciel dont l’utilisation, la modification et la diffusion sont autorisées par une licence qui garantit les libertés fondamentales des utilisateurs. Ces libertés incluent la possibilité d’exécuter, d’étudier, de copier, d’améliorer et de redistribuer le logiciel selon vos besoins.
Inscription | GPS 43.60524/3.87336
Fiche activité:
https://montpellibre.fr/fiches_activites/Fiche_A5_017_Emission_Radio_Montpellibre_2024.pdf
- Radio FM-Plus, 4 rue Saint Barthelemy, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, radio, fm-plus, temps-libre, diffusion
Rencontre mensuelle du groupe OSM Annecy
- Les Carrés – salle Boma, 43 avenue des Carrés, Annecy-le-Vieux, Auvergne-Rhône-Alpes, France
- osm, openstreetmap, cartographie, rencontres
Au cours de cette rencontre, nous commencerons par une brève présentation de nos organisations et des intervenants qui animerons nos échanges et ce groupe. Nous présenterons ensuite les définitions de l’IA générative, en mettant en évidence la distinction entre les modèles fermés, souvent associés à des dynamiques de monopole et d’opacité, et les modèles ouverts, qui encouragent l’innovation, la transparence et la collaboration au sein de la communauté.
L’impact de l’intelligence artificielle sera au cœur de nos discussions, car ces aspects sont essentiels pour encadrer l’utilisation éthique et responsable des contenus générés par celle-ci. Nous examinerons ensemble l’intérêt d’exploiter des solutions d’IA générative ouvertes tout en restant conscients de leurs limitations et des défis qu’elles posent.
Alors, vous l’aurez compris, c’est évidemment une occasion particulièrement intéressante de prendre part à un dialogue constructif pour orienter les travaux, recherches et expérimentations de ce groupe.
- Atelier des Pigistes, 171 bis rue Frimaire, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, logiciels-libres, culture-libre, communs-numeriques, intelligence-artificielle, groupia, open-source, atel'libre
L’émission Libre à vous! de l’April est diffusée chaque mardi de 15 h 30 à 17 h sur radio Cause Commune sur la bande FM en région parisienne (93.1) et sur le site web de la radio.
Le podcast de l’émission, les podcasts par sujets traités et les références citées sont disponibles dès que possible sur le site consacré à l’émission, quelques jours après l’émission en général.
Les ambitions de l’émission Libre à vous!
Découvrez les enjeux et l’actualité du logiciel libre, des musiques sous licences libres, et prenez le contrôle de vos libertés informatiques.
Donner à chacun et chacune, de manière simple et accessible, les clefs pour comprendre les enjeux mais aussi proposer des moyens d’action, tels sont les objectifs de cette émission hebdomadaire.
L’émission dispose:
- d’un flux RSS compatible avec la baladodiffusion
- d’une lettre d’information à laquelle vous pouvez vous inscrire (pour recevoir les annonces des podcasts, des émissions à venir et toute autre actualité en lien avec l’émission)
Radio Cause Commune,
Chacun de nous peut prendre part aux progrès de la science.
Quels que soient vos diplômes, découvrez et contribuez avec nous à divers projets de sciences participatives au cours des ateliers proposés par le Laboratoire Sauvage.
Sujet du jour: Comment trouver les trous noirs cachés, ceux qui ne se nourrissent pas ?
Présentation suivie d’un atelier pratique contributif.
Pour nous trouver, c’est chaque 3ᵉ mardi du mois, mêmes lieu et horaires.
- Espace multimédia, médiathèque Jules Verne, 2 rue de Malines, Vandœuvre-lès-Nancy, Grand Est, France
- https://fccl-vandœuvre.fr/sciences
- laboratoire-sauvage, atelier, numérique, fccl, sciences
Discussion entre contributeurs lyonnais du projet OSM et acteurs intéressés.
Toute personne intéressée par OpenStreetMap peut s’intégrer à cette rencontre, tout particulièrement les débutants qui souhaiteraient des conseils pour se lancer.
Ordre du jour à compléter: https://wiki.openstreetmap.org/wiki/FR:Lyon/Reunion-2025-02-18
Lieu de réunion: Tubà, 15 boulevard Vivier-Merle, Lyon 3ᵉ.
- Tubà, 15 boulevard Vivier-Merle, Lyon, Auvergne-Rhône-Alpes, France
- https://wiki.openstreetmap.org/wiki/FR:Lyon
- osm, openstreetmap, rencontre-mensuelle, contributeurs, données-ouvertes, discussion, logiciels-libres
Bonjour à tous,
Pour notre prochain mardi du libre, nous nous retrouverons à Vergèze, pour une fois un troisième mardi:
- où: Centre socioculturel Marcel Pagnol, 99 rue Marcel Pagnol 30310 Vergèze,
- salle: Topaze, à gauche au rez-de-chaussée, la salle de droite avant l’escalier.
- quand: mardi 18 février 2025, à partir de 18h30
Ce soir-là:
- Atelier débutant sur le logiciel libre FreeCAD, logiciel de dessin 3D, atelier ouvert à tous (1)
Alternative libre à Fusion 3D, vous pourrez destiner vos créations aussi bien à l’impression 3D qu’à la gravure CNC.
Inscription obligatoire, en cliquant sur le lien en bas à droite du site web de gard-linux.fr
PS: en l’absence d’inscription de participants externes avant 16h30 le jour de l’atelier, celui-ci sera annulé.
Alors, n’hésitez pas à nous rejoindre, pour un simple bonjour, ou bien pour discuter plus longtemps.
A mardi !
- Centre socioculturel Marcel Pagnol, 99 rue Marcel Pagnol, 99 rue Marcel Pagnol, Vergèze, Occitanie, France
- https://www.gard-linux.fr
- atelier, logiciel-libre, freecad, gard-linux
La Guilde vous propose deux ateliers en une soirée: install party ET rencontre Fairphone à la Turbine.coop.
Vous en avez assez d’être dépendants des OS et logiciels propriétaires? (Android, etc?) Cet atelier est pour vous! Repartez à la fin de la soirée avec votre propre machine fonctionnant sous un nouveau système d’exploitation, correctement installé, configuré et agrémenté de nombreux logiciels (essentiellement libres!).
C’est aussi l’occasion pour les utilisateurs de FairPhone de partager leurs expériences. Ce mois-ci, un Fairphone 3, un Fairphone 4 et un Fairphone 5 avec /e/OS installé seront disponibles pour démonstration.
Merci de sauvegarder vos données si vous apportez votre machine!
- La Turbine.coop, 5 esplanade Andry Farcy, Grenoble, Auvergne-Rhône-Alpes, France
- https://www.guilde.asso.fr
- install-party, logiciel-libres, guilde, rencontre, fairphone, gnu-linux, linux
Assistance technique et démonstration concernant les logiciels libres.
Il est préférable de réserver votre place à contact (at) linuxmaine (point) org
Planning des réservations consultableici.
- Centre social, salle 220, 2ᵉ étage, pôle associatif Coluche, 31 allée Claude Debussy, Le Mans, Pays de la Loire, France
- https://linuxmaine.org
- linuxmaine, gnu-linux, demonstration, assistance, permanence, logiciels-libres, linux
Venez découvrir GNU/Linux et vous faire aider pour l’installation et à la prise en main, dans différents lieux de l’Hérault.
L’équipe de Montpel’libre vous propose une permanence Logiciels Libres: discussions libres et accompagnement technique aux systèmes d’exploitation libres pour vous aider à vous familiariser avec votre système GNU/Linux au quotidien.
Le contenu de l’atelier s’adapte aux problèmes et aux questionnements des personnes présentes avec leurs ordinateurs, qu’ils soient fixes ou portables. Il permet ainsi l’acquisition de nouvelles compétences nécessaires à une autonomie numérique certaine, au rythme de chacun.
Les personnes débutantes souhaitant découvrir GNU/Linux et apprendre à l’installer et à s’en servir. Les personnes plus expérimentées à la recherche d’une aide technique pour résoudre des problèmes spécifiques. Cet atelier s’adresse à un public adulte et capable d’utiliser un ordinateur.
Possibilité d’installer les variantes d’Ubuntu (Gnome), Ubuntu Mate, Xubuntu (Xfce), Lubuntu (LXDE, LXQt), Kubuntu (KDE Plasma), Ubuntu Budgie. Ubuntu Unity, Ubuntu Cinnamon.
- Médiathèque Gaston Baissette, 106 boulevard de la Liberté, Mauguio, Occitanie, France
- https://montpellibre.fr
- montpel-libre, logiciels-libres, culture-libre, communs-numeriques, gnu-linux, permanence, aide, technique
Cours d’espéranto tous les mercredis de 17h30 à 19h,
Université Bordeaux Montaigne,
Esplanade des Antilles,
Domaine Universitaire
33600 Pessac
Les cours sont animés par Elvezio & Jean-Seb. Ils sont totalement gratuits et sans droits d’inscription à la fac, 100% gratuits.
Veuillez contacter le 06 72 17 22 97 avant votre venue afin de connaître la salle ou pour plus d’informations.
- Université Bordeaux Montaigne, esplanade des Antilles, Pessac, Nouvelle-Aquitaine, France
- https://esperanto-gironde.fr
- neutre, fraternelle, internationale, langue-libre, espéranto
Chaque mercredi soir, l’association propose une rencontre pour partager des connaissances, des savoir-faire, des questions autour de l’utilisation des logiciels libres, que ce soit à propos du système d’exploitation Linux, des applications libres ou des services en ligne libres.
C’est l’occasion aussi de mettre en avant l’action des associations fédératrices telles que l’April ou Framasoft, dont nous sommes adhérents et dont nous soutenons les initiatives avec grande reconnaissance.
- Ecospace, 136 rue de la Mie au Roy, Beauvais, Hauts-de-France, France
- https://www.oisux.org
- oisux, logiciels-libres, atelier, rencontre, sensibilisation
Qu’est-ce que la Ğ1 (June), la monnaie Libre, indépendante de tout état, sans spéculation, avec une création monétaire égalitaire via le Dividende Universel, écologique…
Elle libère l’utilisateur de la banque, de la dette et de toute institution centralisée.
Nous répondrons à vos questions après une présentation.
La sortie est sans obligation de consommation. Votre seule participation sera votre l’adhésion annuelle au café associatif le Petit Grain (tarif libre, conseillé à 5€, minimum 2€). Cette adhésion est valable pour tous les ateliers et pour toute l’année.
N’hésitez pas à me contacter pour plus d’informations, je vous répondrais avec grand plaisir.
- Le Petit Grain, 3 place Dormoy, Bordeaux, Nouvelle-Aquitaine, France
- https://www.yakafaucon.com/le-petit-grain-programme
- monnaie_libre, neutre, june, g1
AlpOSS, Alpes Open Source Software, est de retour pour sa deuxième édition le jeudi 20 février 2025 !
Evénement de l’écosystème open source local et régional, AlpOSS « Alpes Open Source Software » s’adresse aux éditeurs, prestataires de services, collectivités locales et utilisateurs d’open source au sens large. La conférence a pour but de créer du lien entre les fournisseurs de technologies open source innovantes et les utilisateurs, d’échanger autour des modèles de collaboration et modèles d’affaires, et de structurer et dynamiser l’écosystème local.
Co-organisé par la ville d’Echirolles, la communauté open source OW2 et Belledonne communication éditeur grenoblois de la solution Linphone, l’évènement est accueilli par la mairie d’Echirolles et ouvert à tous gratuitement sur inscription en ligne préalable. Il inclut un programme de conférences et ateliers, une zone d’exposition ouverte aux sponsors, ainsi que divers moments de partage pour favoriser les échanges et networking.
- Mairie d’Echirolles, 1 place des cinq fontaines, Echirolles, Auvergne-Rhône-Alpes, France
- https://alposs.fr
- ow2, linphone, opensource, communauté-du-libre, communauté, alposs
Programmation des Ateliers du Libre 2025
De janvier à mai 2025, Résoudre vous propose 6 ateliers numériques de 3 séances pour découvrir les logiciels libres (gratuits).
TRAITEMENT DE TEXTE
TABLEAU DE CALCUL
DIAPORAMA
TRAITEMENT VIDEO
RETOUCHE PHOTO
MIXAGE AUDIO
OUVERT TOUT PUBLIC, Inscrivez-vous à l’accueil.
Participation sous forme d’adhésion 10 € par atelier de 3 séances.
Télécharger ici la programmation «Ateliers du Libre 2025»
- Accès rue Ampère, Association Résoudre – 4 rue Lavoisier, Joué-lès-Tours, Centre-Val de Loire, France
- https://resoudre37.fr/ateliers-a-la-carte-de-decouverte-des-logiciels-libres
- résoudre, atelier, atelier-du-libre, libreoffice, logiciels-libres
- de 18h – 20h
- Contributions à l’association (Aquarium): Cette session permet de contribuer à l’administration de l’association. C’est l’occasion pour les membres de s’impliquer dans la gestion de l’association sans être élu du CA.
- Atelier au Fablab (TeenLab): Cet atelier est axé sur la domotique et l’électronique. Les participants peuvent apprendre et travailler sur des projets liés à ces domaines. En partenariat avec le FabLab.
- de 20h – 22h: Contributions au Libre (TeenLab) – Durant cette période, des travaux pratiques sur les logiciels libres sont réalisés. Les participants contribuent directement à des projets libres en cours.
Ces événements sont conçus pour encourager l’apprentissage, le partage et la contribution dans le domaine des technologies libres et de l’électronique.
- La Dynamo, 24 avenue Daniel Rops, Chambery, Auvergne-Rhône-Alpes, France
- https://alpinux.org
- libre, alpinux, contribution, atelier
J’organise une présentation de l’Espéranto, la langue internationale très facile à apprendre, fraternelle, neutre et libre au Café Le Petit Grain, Place Dormoy à Bordeaux (c’est un café associatif avec des tarifs abordables dans le quartier de la gare Saint-Jean à côté de Barbey).
Ce sera l’occasion de découvrir autour d’un verre ce qu’est l’Espéranto, pourquoi a-t-il été créé, comment, qui l’utilise…
Cette vidéo vous permettra d’en savoir plus et nous répondrons à toutes vos questions: https://flim.txmn.tk/w/57p7HNerYxBrfDnSG4RKdd
Vous trouverez également plus d’informations sur: https://esperanto-gironde.fr/lesperanto/, il y a l’abonnement à la lettre d’informations mensuelle qui est proposée en fin de chaque page afin de rester informé des activités espérantistes du coin.
Ce sera aussi l’occasion de pratiquer pour les espérantistes.
La soirée est ouverte à tous et toutes, espérantistes ou non.
La sortie est gratuite sans obligation de consommation. Votre seule participation sera votre éventuelle consommation et l’adhésion au café associatif le Petit Grain si vous consommez (tarif libre, conseillé à 5€, minimum 2€).
- Le Petit Grain, 3 place Dormoy, Bordeaux, Nouvelle-Aquitaine, France
- espéranto, langue-libre, decouverte, le-petit-grain
Avec des bénévoles d’OpenStreetMap
©OpenStreetMap France
OpenStreetMap est la carte ouverte et collaborative du monde entier, améliorée chaque jour par plus d’un million de contributrices et contributeurs. Venez rencontrer celles et ceux qui font vivre cette carte et découvrir une alternative libre à Google Maps.
Ce café sera suivi d’un atelier d’initiation à la contribution le 15 mars.
Tout public, entrée libre dans la limite des places disponibles ou sur réservation sur le site du Rize
- Le Rize, 23 rue Valentin Hauy, Villeurbanne, Auvergne-Rhône-Alpes, France
- https://lerize.villeurbanne.fr/agenda/decouvrir-openstreetmap-la-carte-libre-dont-vous-etes-les-heros/
- cartographie, osm, openstreetmap
Un apéro April consiste à se réunir physiquement afin de se rencontrer, de faire plus ample connaissance, d’échanger, de partager un verre et de quoi manger mais aussi de discuter sur l’actualité et les actions de l’April.
Ce rendez-vous est « hybriditiel » ou « hybridiciel », c’est à dire qu’il sera à la fois en présentiel et en distanciel.
Un apéro April est ouvert à toute personne qui souhaite venir, membre de l’April ou pas. N’hésitez pas à venir nous rencontrer.
Les apéros April ont lieu chaque mois à Paris, Marseille et à Montpellier.
Régulièrement Montpel’libre relaie et soutient les actions de l’April. De nombreux Apriliens ont par ailleurs rejoints les rangs de Montpel’libre, lors d’événements tels que les Apéros April, l’AprilCamp ou les Rencontres Mondiales du Logiciel Libre qui ont eu lieu à Montpellier et bien sûr de nombreux Montpel’libristes sont adhérents de l’April.
Nous vous invitons donc à venir nous rejoindre dans une ambiance conviviale, à partager cet apéro, chacun porte quelque chose, boissons, grignotages… et on partage.
Les discussions de ce mois-ci se porteront sur l’actualité de moment.
Entrée libre et gratuite sur inscription. Une simple adhésion à l’association est possible. Rejoindre le groupe Montpel’libre sur Telegram S’inscrire à l’Infolettre de Montpel’libre.
Tramway lignes 1 et 3, arrêts Port-Marianne et Rives du Lez
GPS Latitude : 43.603095 | Longitude : 3.898166
Carte OpenStreetMap
https://montpellibre.fr/fiches_activites/Fiche_A5_020_Rendez-vous_Aprilapero_Montpellibre_2024.pdf
- Atelier des Pigistes, 171 rue Frimaire, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, april, apero, rencontre, logiciel-libres
L’Apéro des Quatre Libertés reprend, interprète et autant que faire se peut, augmente les travaux de l’April, de La Quadrature Du Net, de la Free Software Fondation, la Free Software Fondation Europe et bien d’autres comme Les exégètes amateurs ou Open Law…
Cet apéro a lieu le troisième jeudi de chaque mois.
Ce rendez-vous est hybride, c’est-à-dire qu’il sera à la fois en présentiel et en distanciel.
Les discussions de ce mois-ci se porteront sur l’actualité du moment.
Entrée libre et gratuite sur inscription. Une simple adhésion à l’association est possible.
Rejoindre le groupe Montpel’libre sur Telegram. S’inscrire à l’Infolettre de Montpel’libre.
Tramway lignes 1 et 3, arrêts Port-Marianne et Rives du Lez
GPS Latitude : 43.603095 | Longitude : 3.898166
Carte OpenStreetMap
- Atelier des Pigistes, 171 rue Frimaire, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, april, quadrapero, fsf, rencontre, logiciels-libres, culture-libre, biens-communs, apéro
Afin de se rencontrer, d’échanger et de faire plus ample connaissance, Montpel’libre lance de nouvelles rencontres surnommées les FSFapéros. C’est l’occasion pour les neurones de toutes parts de se réunir physiquement pour discuter, échanger et partager un verre et de quoi grignoter.
Ce rendez-vous est «hybriditiel» ou «hybridiciel», c’est-à-dire qu’il sera à la fois en présentiel et en distanciel.
Les FSFapéros auront lieu tous le 3ᵉ jeudi de chaque mois. Ils sont l’occasion de discussions informelles d’une part et de discussions plus sérieuses sur les différents thèmes d’importance et les différentes actions et campagnes en cours.
Tout le monde est invité et peut venir aux FSFapéros, qu’on soit contributeur de longue date, simple intéressé-e par les sujets que défend la Free Software Foundation Europe, ou nouvel-le arrivant-e cherchant à participer davantage. N’hésitez pas à amener vos amis et à leur faire découvrir la Free Software Foundation, et Montpel’libre.
Peuvent être aussi abordées des questions sur Les exégètes amateurs ou Open Law.
Les discussions de ce mois-ci se porteront sur l’actualité de moment.
Entrée libre et gratuite sur inscription. Une simple adhésion à l’association est possible. Rejoindre le groupe Montpel’libre sur Telegram S’inscrire à l’Infolettre de Montpel’libre.
Tramway lignes 1 et 3, arrêts Port-Marianne et Rives du Lez
GPS Latitude: 43.603095 | Longitude: 3.898166
Carte OpenStreetMap
- Atelier des Pigistes, 171 rue Frimaire, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, fsf, permanence, logiciels-libres, fsfapero
Afin de se rencontrer, d’échanger et de faire plus ample connaissance, Montpel’libre lance de nouvelles rencontres surnommées les Quadrapéros. C’est l’occasion pour les neurones de toutes parts de se réunir physiquement pour discuter, échanger et partager un verre et de quoi grignoter.
Ce rendez-vous est «hybriditiel» ou «hybridiciel», c’est-à-dire qu’il sera à la fois en présentiel et en distanciel.
Les Quadrapéros auront lieu tous le 3ᵉ jeudi de chaque mois. Ils sont l’occasion de discussions informelles d’une part et de discussions plus sérieuses sur les différents thèmes d’importance et les différentes actions et campagnes en cours.
Tout le monde est invité aux Quadrapéros, qu’on soit contributeur ou contributrice de longue date, simple intéressé par les sujets que défend la Quadrature, ou nouvel arrivant cherchant à participer davantage. N’hésitez pas à amener vos amis et à leur faire découvrir La Quadrature et Montpel’libre.
Peuvent être aussi abordées des questions sur Les exégètes amateurs ou Open Law.
Les discussions de ce mois-ci se porteront sur l’actualité de moment.
Entrée libre et gratuite sur inscription. Une simple adhésion à l’association est possible.
Tramway lignes 1, 2, 3 et 4, arrêts Gare Saint-Roch
GPS Latitude: 43.60285 | Longitude: 3.87927
Carte OpenStreetMap
- Atelier des Pigistes, 171 rue Frimaire, Montpellier, Occitanie, France
- https://montpellibre.fr
- montpel-libre, apero, logiciels-libres, quadrapero, lqdn, la-quadrature-du-net, culture-libre, communs-numeriques
Venez à la Maison de quartier des Glacis pour découvrir les Logiciels Libres.
Vous utilisez déjà des logiciels libres, et ceux-ci font tourner Internet: pourquoi, alors, ne pas les utiliser avec nos ordinateur, à la place de logiciels privateurs, source d'obsolescence programmée, et si souvent curieux et indiscrets quant à nos données personnelles ?
Venez avec un ordinateur portable si vous le souhaitez, vous pourrez tester un environnement complet de logiciels libres basés sur le système GNU-Linux, sans rien modifier à votre machine (aucune lecture ni écriture n’a lieu sur le disque dur). Il s’agit de faire la démonstration du potentiel d’un bouquet de logiciels libres, et de montrer leurs qualités:
- légèreté, rapidité
- prise en compte de tous les formats de données courants (texte, image, vidéo)
- gratuité (par défaut, la copie est légalement permise !)
- pertinence
Cette introduction est le début d’un cycle de rencontres mensuelles, qui vous permettront de vous approprier les Logiciels Libres, et de former un groupe de voisines, de voisins, avec une connaissance à partager.
- Maison de quartier des Glacis, 8 rue de l’Adroit, Dunkerque, Hauts-de-France, France
- libre-en-fete-2025, logiciel-libre, apprendre, linux, gnu-linux
Rencontres mensuelles autour de Guix.
Venez découvrir, discuter et contribuer à Guix dans une ambiance conviviale.
Il n’y a pas d’expérience pré-requise et vous êtes tout·es les bienvenu·es.
Programme
Les soirées se déroulent en 3 temps :
- 19h-20h : accueil et discussions libres ;
- 20h-21h : présentation autour d’un sujet spécifique suivie d’une session de questions/réponses ;
- 21h-22h : ateliers de contribution et discussions libres.
Bien sûr, les horaires sont donnés à titre complètement indicatif ! _'
Logistique
S’inspirant des apéro’ April, chacun·e est invité·e à amener un petit quelque chose à manger et/ou à boire afin de pouvoir partager avec les autres participant·es.
Accès
Nous serons accueilli·es dans les locaux de l'April, elle-même hébergée par Easter-eggs :
Association April
44/46 rue de l’Ouest (cour intérieure)
Bâtiment 8
75014 Paris
Stations de Métro: Gaîté, Montparnasse, Pernety.
OpenStreetMap: <https://www.openstreetmap.org/node/3199095063>.
Au plaisir de vous y rencontrer !
- April, 44-46 rue de l’Ouest, Paris, Île-de-France, France
- https://guix.gnu.org
- guix, guile, linux, logiciels-libres, rencontre-mensuelle
L’AGU3L Logiciels Libres à Annecy votre association se réuni tous les vendredis à partir 20h00 et jusque vers 1h00 du matin. Passez quand vous voulez.
Entrée par le côté, entre les 2 bâtiments la MJC le Cairn et la maison des associations. La salle est au fond du couloir à droite, là où il y a de la lumière.
⚠️ Vérifiez sur le site avant de vous déplacer, y a un bandeau en haut qui confirme bonne la tenue de la réunion.
Le programme de la réunion, s’il y en a un, est sur notre site.
Lettre d'information XMPP de novembre 2024
N. D. T. — Ceci est une traduction de la lettre d’information publiée régulièrement par l’équipe de communication de la XSF, essayant de conserver les tournures de phrase et l’esprit de l’original. Elle est réalisée et publiée conjointement sur les sites XMPP.org, LinuxFr.org et JabberFR.org selon une procédure définie.
Bienvenue dans la lettre d'information XMPP, ravi de vous retrouver !
Ce numéro couvre le mois de novembre 2024.
Tout comme cette lettre d'information, de nombreux projets et leurs efforts dans la communauté XMPP résultent du travail bénévole des personnes.
Si vous êtes satisfait des services et des logiciels que vous utilisez, merci de considérer dire merci ou aider ces projets !
Vous souhaitez soutenir l'équipe de la lettre d'information ? Lisez en bas de page.
- Annonces XSF
- Événements XMPP
- Articles XMPP
- Actualité des logiciels XMPP
- Extensions et spécifications
- Partagez les nouvelles
- Aidez-nous à construire la lettre d'information
- Licence
La XSF planifie le Sommet XMPP 27, qui se tiendra les 30 et 31 janvier 2025 à Bruxelles (Belgique, Europe). À la suite du Sommet, la XSF prévoit également d’être présente au FOSDEM 2025, qui aura lieu les 1er et 2 février 2025. Retrouvez tous les détails dans notre Wiki. Inscrivez-vous dès maintenant si vous prévoyez d'y assister, cela aide à l'organisation. L'événement est bien sûr ouvert à toutes les personnes intéressées à participer. Faites passer le mot dans vos cercles !
Hébergement fiscal de projets par la XSFLa XSF propose un hébergement fiscal pour les projets XMPP. Vous pouvez postuler via Open Collective. Pour plus d’informations, consultez le post de blog d’annonce. Les projets actuels que vous pouvez soutenir :
Événements XMPP- Berlin XMPP Meetup (DE / EN) : réunion mensuelle des passionnés de XMPP à Berlin, chaque 2ème mercredi du mois à 18h, heure locale
- XMPP Italian happy hour [IT] : réunion mensuelle XMPP en ligne en italien, chaque troisième lundi du mois à 19h00, heure locale (événement en ligne, avec mode réunion web et streaming en direct).
- ProcessOne
- Erlang Solution
- XMPP : le joyau oublié de la messagerie instantanée. Une exploration bien pensée sur XMPP, pourquoi il n’a pas atteint une adoption généralisée, pourquoi il reste pertinent et comment il pourrait être la meilleure option pour ceux qui recherchent un outil de messagerie flexible, sécurisé et open-source.
- Le guide rapide et facile de Jabber/XMPP
- XMPP pour les navigateurs : Une idée pour développer des logiciels de navigateur avec XMPP PubSub.
- Facile guida per chattare con XMPP [IT] : Un guide facile pour discuter en utilisant XMPP (également disponible en anglais)
- Conversations a publié les versions 2.17.3 et 2.17.4 pour Android.
- Monocles Chat 2.0.2 a été publié. Cette version apporte MiniDNS, l'exportation des paramètres, des corrections et plus encore !
- Monal a publié la version 6.4.6 pour iOS et macOS.
- Cheogram a publié la version 2.17.2-2 pour Android. Cette version apporte une fonctionnalité de demandes de chat pour cacher les SPAM possibles, avec une option pour tout signaler. De plus, elle contient plusieurs améliorations et corrections de bugs. À noter également, depuis novembre dernier, Cheogram est de nouveau disponible en téléchargement sur le Google Play Store !
- Openfire 4.9.1 et 4.9.2 ont été publiés. La version 4.9.1 est une mise à jour de correction de bugs et de maintenance, tandis que la version 4.9.2 est une mise à jour de correction de bugs. Vous pouvez consulter le journal des modifications complet pour plus de détails.
- MongooseIM version 6.3.0 a été publiée. Le principal point fort est la refonte complète de l'instrumentation, permettant l'intégration avec Prometheus. De plus, CockroachDB a été ajouté à la liste des bases de données prises en charge pour une évolutivité accrue. Consultez les notes de version pour plus d'informations.
- L'application (non officielle) Prosody pour Yunohost a maintenant atteint une maturité bêta, l'ouvrant à tout le monde pour des tests. Cette variante vise à fournir un meilleur support XMPP pour les utilisateurs de Yunohost. Par rapport aux applications officielles Metronome et Prosody, cette application permet d'activer les appels audio/vidéo par défaut. Une importation optionnelle des listes de contacts, MUC et favoris depuis Metronome est également proposée. Pour rappel, Yunohost est une distribution de serveur basée sur Debian, ce qui facilite l'hébergement de nombreux services (applications) par soi-même. Jusqu'à la dernière version majeure (version 12), Metronome était intégré à l'installation de base, permettant à de nombreuses personnes de découvrir plus facilement XMPP (bien qu'avec certaines limitations).
- go-xmpp versions 0.2.5, 0.2.6 et 0.2.7 ont été publiées.
- go-sendxmpp versions 0.12.0 et 0.12.1 ont été publiées.
- QXmpp versions 1.9.0 et 1.9.1 ont été publiées.
- Slidge versions v0.2.1 et v0.2.2 ont été publiées, apportant plusieurs corrections de bugs.
La XMPP Standards Foundation développe des extensions pour XMPP dans sa série XEP en plus des RFC XMPP.
Des développeuses, développeurs et experts en normes du monde entier collaborent sur ces extensions, élaborant de nouvelles spécifications pour des pratiques émergentes et affinant les méthodes existantes. Proposées par n'importe qui, celles qui rencontrent un grand succès finissent par être classées comme Final ou Active, selon leur type, tandis que d'autres sont soigneusement archivées comme Deferred. Ce cycle de vie est décrit dans XEP-0001, qui contient les définitions formelles et canoniques des types, états et processus. En savoir plus sur le processus des normes. La communication autour des normes et des extensions se fait sur la liste de diffusion des standards (archive en ligne).
Extensions proposéesLe processus de développement des XEP commence par la rédaction d'une idée et sa soumission à l'éditeur XMPP. Dans un délai de deux semaines, le Conseil décide si cette proposition doit être acceptée comme une XEP expérimentale.
- Aucune XEP proposée ce mois-ci.
- Version 0.1.0 de XEP-0496 (Relations entre nœuds Pubsub)
- Promue à Expérimental (Éditeur XEP : dg)
- Version 0.1.0 de XEP-0497 (Abonnements étendus Pubsub)
- Promue à Expérimental (Éditeur XEP : dg)
- Version 0.1.0 de XEP-0498 (Partage de fichiers Pubsub)
- Promue à Expérimental (Éditeur XEP : dg)
- Version 0.1.0 de XEP-0499 (Découverte étendue Pubsub)
- Promue à Expérimental (Éditeur XEP : dg)
- Version 0.1.0 de XEP-0500 (Mode lent MUC)
- Promue à Expérimental (Éditeur XEP : dg)
Si une XEP expérimentale n’est pas mise à jour pendant plus de douze mois, elle sera déplacée de la catégorie Expérimental vers Déférée. Si une mise à jour survient, la XEP sera remise dans la catégorie Expérimental.
- Aucune XEP déférées ce mois-ci.
- Version 1.0.1 de XEP-0490 (Synchronisation des messages affichés)
- Correction de certains exemples, ainsi que de leur indentation.
- Ajout du schéma XML. (egp)
Les appels finaux sont lancés une fois que tout le monde semble satisfait de l'état actuel de la XEP. Après que le Conseil décide si la XEP semble prête, l'Éditeur XMPP émet un dernier appel pour les commentaires. Les retours recueillis pendant cet appel peuvent aider à améliorer la XEP avant de la renvoyer au Conseil pour son passage en statut stable.
Aucun dernier appel ce mois-ci.
- Version 1.0.0 de XEP-0490 (Synchronisation des messages affichés)
- Acceptée comme stable selon le vote du Conseil du 2024-11-05. (Éditeur XEP (dg))
- Aucune XEP n'a été dépréciée ce mois-ci.
- Aucune XEP n'a été rejeté ce mois-ci.
Veuillez partager la nouvelle sur d'autres réseaux :
- Mastodon
- YouTube
- Instance Lemmy (non officielle)
- Reddit (non officiel)
- Page Facebook XMPP (non officielle)
Consultez aussi notre flux RSS !
Vous recherchez des offres d'emploi ou souhaitez engager un consultant professionnel pour votre projet XMPP ? Visitez notre tableau d'offres d'emploi XMPP.
Contributions à la lettre d'informations et traductionsIl s'agit d'un effort communautaire, et nous tenons à remercier les traducteurs pour leurs contributions. Les bénévoles et plus de langues sont les bienvenus ! Les traductions de la lettre d'information XMPP seront publiées ici (avec un certain délai) :
- Anglais (original) : xmpp.org
- Contributions générales : Adrien Bourmault (neox), Alexander "PapaTutuWawa", Arne, cal0pteryx, emus, Federico, Gonzalo Raúl Nemmi, Jonas Stein, Kris "poVoq", Licaon_Kter, Ludovic Bocquet, Mario Sabatino, melvo, MSavoritias (fae,ve), nicola, Schimon Zachary, Simone Canaletti, singpolyma, XSF iTeam
- Français : jabberfr.org et linuxfr.org
- Traductions : Adrien Bourmault (neox), alkino, anubis, Arkem, Benoît Sibaud, mathieui, nyco, Pierre Jarillon, Ppjet6, Ysabeau
- Italien : notes.nicfab.eu
- Traductions : nicola
- Espagnol : xmpp.org
- Traductions : Gonzalo Raúl Nemmi
- Allemand : xmpp.org
- Traductions : Millesimus
Cette lettre d'information XMPP est produite de manière collaborative par la communauté XMPP. Chaque numéro de la lettre d'information mensuelle est rédigé dans ce pad simple. À la fin de chaque mois, le contenu du pad est fusionné dans le dépôt Github de la XSF. Nous sommes toujours heureux d'accueillir des contributeurs. N'hésitez pas à rejoindre la discussion dans notre chat de groupe Comm-Team (MUC) et ainsi nous aider à maintenir cet effort communautaire. Vous avez un projet et souhaitez faire connaître vos nouvelles ? Veuillez envisager de partager vos actualités ou événements ici et de les promouvoir auprès d'un large public.
Tâches que nous accomplissons régulièrement :
- rassembler les nouvelles de l'univers XMPP
- résumés brefs des nouvelles et événements
- résumé de la communication mensuelle sur les extensions (XEPs)
- révision du brouillon de la lettre d'information
- préparation d'images pour les médias
- traductions
- communication via les comptes des médias
Cette lettre d'information est publiée sous la licence CC BY-SA.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur

Inscrivez-vous aujourd'hui à l'infolettre pour découvrir les enjeux du logiciel libre, des outils et des moyens d'actions. Prenez le contrôle de vos libertés informatiques. Suivez nos actions en cours et à venir.









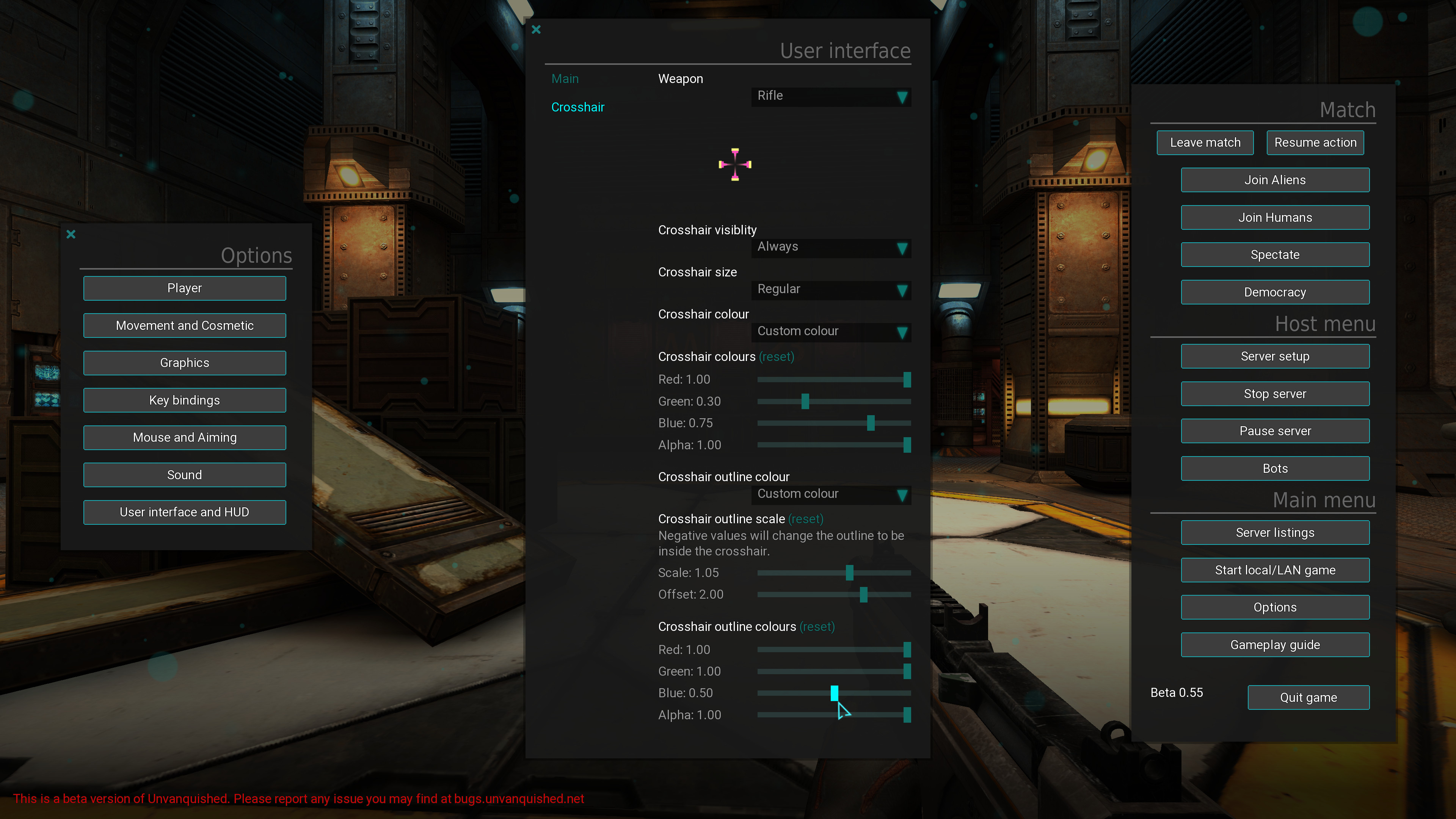{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}